En el mundo del Business Intelligence (BI) es muy importante tener un datawarehouse para tener toda la información obtenida de distintas fuentes centralizada en una misma base de datos. Además, esta información debe estar normalizada y por esa razón escribo este artículo sobre los modelos de estrella, pilar fundamental y no único de cualquier datawarehouse.
Antes de empezar a definir el modelo de estrella me voy a permitir el lujo de hablar muy brevemente sobre Kimball e Inmon y que proponen cada uno de ellos, además, luego explicaré el modelo de estrella y su rival, el modelo en copo de nieve.
Kimball
Enlace: https://blog.bi-geek.com/arquitectura-el-enfoque-de-ralph-kimball/
Para diseñar un datawarehouse se tiene que conocer muy bien el negocio pero ¿qué pasa si no se conoce o se trabaja en una consultora? ¿Tenemos que invertir muchísimo tiempo en conocer todos los procesos de negocio, entenderlos, dominarlos para después diseñar el datawarehouse? La respuesta es NO TIENE PORQUE.
La filosofía que propone Kimball es la de “Bottom-up”, filosofía que también se sigue en el desarrollo de software y consiste en empezar por tareas sencillas y conforme se va avanzando en el proyecto este va evolucionando.
Si pensamos un poco, esta filosofía empieza de unas necesidades básicas creando un primer modelo que solo dará respuesta a pocos usuarios de la empresa, por lo que el datawarehouse en este momento es equivalente a un datamart. Cuando se tiene este datamart funcionando perfectamente, se sigue desarrollando otros modelos que cubran las necesidades de otros departamentos y ahora sí podríamos estar hablando de un datawarehouse.
La clave de tener en un mismo datawarehouse todos los modelos es que las dimensiones se comparten entre modelos.
La estructura de este datawarehouse podría ser grandes tablas desnormalizadas con toda la información, modelos de estrella o modelos de copo de nieve.
Desde mi punto de vista el modelo de estrella es el mejor por mantenibilidad, reutilización de las dimensiones y menor cantidad de campos en las tablas de hechos.
Inmon
Enlace: https://blog.bi-geek.com/arquitectura-enfoque-de-william-h-inmon/
Inmon propone tener en un datawarehouse distintos datamarts, hablando de forma práctica esto es que por cada modelo de datos o tabla de hechos tenga sus propias dimensiones pudiendo tener por ejemplo la dimensión CLIENTE repetida en distintos datamarts. Cada departamento dentro de la empresa tendría su propio datamart con sus datos.
Inmon exige además tener una estructura de datos normalizada hasta la tercera forma normal 3FN (la mayoría de aplicaciones web están normalizadas en esta forma y son fundamentos de base de datos).
3FN: https://es.wikipedia.org/wiki/Tercera_forma_normal
La estructura que exige Inmon es la de copo de nieve (no la de estrella) que penaliza el rendimiento por hacer uso de una gran cantidad de joins. Mi pregunta es ¿Si exige tener un modelo de copo de nieve, porque no hacer consultas directamente a la base de datos? El rendimiento sería muy parecido.
Mi experiencia usando Kimball
Desde mi experiencia, en Planeta Huerto cuando empecé a desarrollar el datawarehouse no conocía el negocio y paralelamente a la construcción del datawarehouse mis compañeros iban solicitando datos e informes de una base de datos que no conocía. Gracias a estos informes que día a día sacaba y con ayuda de los desarrolladores que me explicaban la estructura de la BBDD iba entendiendo como esta estaba estructurada.
Seguí la filosofía de Kimball y trabajé con una estrategia “Bottom-up”, conforme iban entrando requerimientos iba añadiendo al datawarehouse nuevas métricas y campos a las dimensiones. También iba generando nuevos modelos consiguiendo tener modelos que satisfacían las necesidades a los departamentos:
- Marketing
- Producto
- Finanzas
- Stock
- Visión General
Desde mi punto de vista, usar kimball es trabajar de forma ágil, en cualquier momento puede cambiar un requerimiento. Si hubiera usado Inmon creo que después de 8 meses aún seguiría haciendo un análisis o directamente en el paro.
Modelo de estrella
Desde mi punto de vista el modelo de estrella es el más práctico a la hora de diseñar un datawarehouse, es el que uso yo en mi día a día por lo siguiente:
- Comparto dimensiones entre distintas tablas de hecho
- Actualizo una dimensión y se refleja en todos los modelos e informes
- Quito la complejidad del copo de nieve, tengo dimensiones con bastantes campos (muchos valores repetidos) pero merece la pena tenerlo así.
- Se tiene muchas menos tablas pero más grande con más información. Esto es bueno porque en la dimensión de producto sabes que encontrarás la marca, categoría, familia, proveedor… estos datos en un modelo de copo de nieve sería dimensiones independientes.

En esta imagen se aprecia como la dimensión Vehículo si se usara el copo de nieve los campos modelo y categoría serían tablas independientes haciendo bastante más complejo hacer una consulta.
Modelo de copo de nieve
En un mundo ideal este modelo sería el ideal pero no lo es, diseñando un modelo en copo de nieve conseguiríamos tener un datawarehouse normalizado en la 3FN. Así es como funcionan todas las bases de datos transaccionales como los ecommerce etc… pero no creo que para un sistema analítico esto sea necesario por las siguientes razones.
- Tener muchas tablas nos obliga a hacer multitud de joins
- Cada join ralentiza muchísimo una consulta, con tablas de 100 registros no pasa nada pero con tablas de 20 millones nos da tiempo a dar muchos likes en tinder
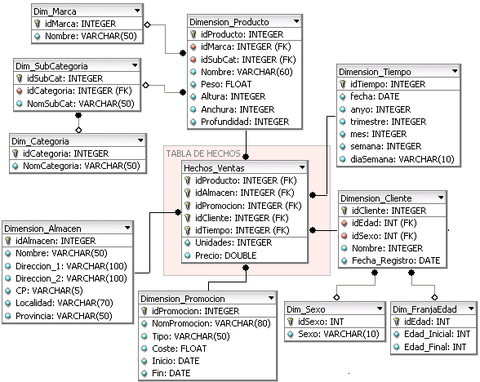
Como se ve en esta imagen, está todo normalizado en la 3FN pero ¿es necesario?
Por ejemplo, en la dimensión cliente el sexo y la franjaEdad las incluiría dentro de cliente aunque estos valores se repitan muchas veces, nos ahorramos dos joins
En la dimensión SubCategoría añadiría los datos de Categoría aunque se repita el nombre de categoría.
Aplicando estas 3 recomendaciones ya se hubiera ahorrado 3 joins para hacer una consulta sobre estas dimensiones.
Conclusión
No obsesionarse con hacer un super análisis, hacer un pequeño análisis inicial y empezar con un pequeño datamart, este ya irá evolucionando conforme vayan entrando necesidades de negocio y con cada nuevo informe que solicitan (consultando la BBDD transaccional) ir diseñando el nuevo modelo de datos.
No usar super tablas desnormalizadas, eso es pan para hoy y hambre para mañana. Con el tiempo van aumentando la cantidad de supertablas y mantener esas tablas como por ejemplo añadir un campo a una dimensión que se encuentran en 5 tablas es hacer 5 modificaciones.
No obsesionarse con tener un modelo en copo de nieve muy normalizado, perjudicará las consultas cuando se hagan joins.
Utilizar un modelo de estrella aplicando el sentido común, por ejemplo, si una dimensión tiene una cantidad de campos muy elevada se puede usar un híbrido entre el modelo de estrella y el copo de nieve.
Hay dimensiones como la dimensión producto que contienen datos del proveedor, podemos decidir incluir todos los datos del proveedor en la misma tabla de producto o desacoplarla de producto teniendo así una nueva dimensión proveedor. (Esto es lo que he hecho yo).
Aplicar el sentido común aunque este sea diferente para cada uno.
Puede ver otros posts relacionados:
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] En el siguiente enlace se puede consultar que és un modelo de estrella: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] Original Post: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] la SUITE de Microsoft. En este artículo voy a mostrar como construir un proceso ETL y cargar un Modelo de Estrella a partir de un Fichero […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] El modelo de estrella. El pilar fundamental del Business Intelligence: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] este artículo http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ explico porque el modelo de estrella es fundamental para un proyecto de Business […]
[…] http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]
[…] En este otro enlace explico el “El modelo de estrella. El pilar fundamental del Business Intelligence”: http://datamanagement.es/blog/2019/06/27/business-intelligence-modelo-estrella/ […]