Introducción
Mi nombre es Francisco Rodriguez Alfaro consultor Senior Business Intelligence, Graduado en Ingeniería Informática por la universidad Miguel Hernández de Elche y máster en Data Management en OBS.
Con este nuevo artículo pretendo explicar desde mi experiencia como consultor de BI los pasos necesarios a seguir para el desarrollo de un proyecto de BI desde cero y los puntos críticos y más importantes para no fallar en el intento. Un buen análisis y planteamiento inicial ahorra muchas horas de desarrollo y parches en cualquier proyecto.
Objetivo
El objetivo de este artículo es el de desarrollar un pequeño proyecto de Business Intelligence (BI) siguiendo las fases más críticas e importantes para que el desarrollo no fracase.
Las fases de un proyecto de BI son las siguientes:
- Entender los requerimientos del cliente y qué información visualizar para analizar.
- Identificación de los orígenes de datos para satisfacer los requerimientos del cliente.
- Estructura básica de ETL con Pentaho
- Extraer/importar la información al área temporal (datastage) para centralizar y trabajar cómodamente con ella.
- Dimensiones
- Métricas
- La estructura del proceso ETL
- Diseñar un modelo de datos analítico (modelo de estrella)
- Probar que la información del modelo es la misma que la del origen
Entender los requerimientos del cliente y qué información visualizar para analizar.
Esta es una fase crítica, se ha de reunir con el cliente y tomar todos los requerimientos que necesita, además, hay que entender al cliente que necesita y para qué, si es necesario hay que aprender del negocio para dar sentido a sus necesidades.
Es muy importante también en esta fase, como consultores que somos, asesorar y guiar al cliente que cosas puede y no se pueden hacer, explicarles porque el BI es más que un simple informe donde aparecen datos y gráficos.
En esta fase el consultor se tiene que convertir en un asesor que guíe e indique los pasos a seguir para el desarrollo e implantación del sistema BI.
Identificación de los orígenes de datos para satisfacer los requerimientos del cliente.
Esta fase es la más crítica para el desarrollo del proyecto, después de la toma de requerimientos, haber entendido y dado sentido a las necesidades del cliente etc… se debe hacer un análisis técnico para identificar los orígenes de datos.
La frase anterior es muy teórica y abstracta así que voy a centrarme más en la práctica y como hacer este análisis desde mi experiencia y olvidarme de tanta teoría.
Yo suelo partir de los requerimientos del cliente y como sería el resultado final para identificar las dimensiones y medidas que el cliente ha definido.
Por ejemplo este informe que quieren tener: “Necesitamos ver en un cuadro de mandos (Dashboard) la cantidad de pedidos diferenciado por el estado de los pedidos en los que se encuentran, además, necesitamos verlo por día para identificar que días se produce un cuello de botella en el almacén o qué días se cancelan más pedidos para después saber porque se cancelan tantos ese día”

Este es el prototipo del dashboard que se ha diseñado conjuntamente con el cliente.
Con la información obtenida anteriormente ahora se puede hacer un pequeño análisis de la información que necesitamos para satisfacer esta necesidad.
Se identifica dos dimensiones:
- Estado del pedido
- Fecha Solicitud del pedido
Se identifica una métrica:
- Cantidad de pedidos
Pues bien, si esto lo hacemos con todos los informes que solicitan/necesitan, muchos de ellos tendrán dimensiones compartidas incluso las métricas también pueden ser compartidas y como resultado final podríamos tener algo como:
Dimensiones de todos los Dashboards:
- Estado del pedido
- Fecha de solicitud
- Fecha de envío
- Cliente
- Proveedor
- Producto
- Descuento Aplicado
- Provincia
Métricas de todos los Dashboards:
- Cantidad de pedidos
- Cantidad de pedidos con incidencias
- Cantidad de pedidos con retrasos
- Total facturación de pedido (suma de facturación líneas de pedido + gastos de envío + donaciones)
- Total facturación (línea de pedido sin gastos de envío y sin donaciones)
- Facturación sin IVA
Estructura básica de ETL con Pentaho
En esta entrada de blog explico como configurar Pentaho para que al ejecutarlo haga uso de la configuración .kettle del proyecto base que adjunto:
Enlace configuración:
Enlace configuración: https://datamanagement.es/2019/08/12/configuracion-pentaho-varios-proyectos/
Proyecto base:
Estructura del proyecto Base.
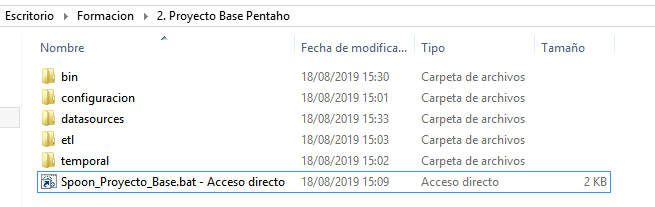
- Bin: En esta carpeta se tienen que añadir los scripts que ejecutan los JOBS o Transformaciones de kettle
- configuration: Aquí va la carpeta .kettle que es la configuración del proyecto donde se les da valor a las variables y conexiones
- datasources: Aquí va los ficheros adicionales como puede ser un fichero de maestras etc… Suelen ser ficheros excel y sirven para complementar la información de las BBDD. En el ejemplo he adjuntado un excel con las provincias de españa y su código.
- etl:Aquí se encuentran todos los JOBS y transformaciones que componen el proceso ETL
- temporal: Esta carpeta sirve para almacenar ficheros que se crean de forma temporal como por ejemplo crear un fichero csv para después adjuntarlo por correo o descargar un fichero por SFTP para después procesarlo
Extraer/importar la información al área temporal (datastage) para centralizar y trabajar cómodamente con ella.
Para llegar hasta este punto aún no se ha necesitado trabajar con pentaho porque el trabajo ha sido puramente análisis e identificación de las fuentes de datos (como alimentar el BI).
Ahora que ya se tiene identificadas las dimensiones y métricas y dibujados los prototipos para entender las necesidades del cliente, se debe proceder a la extracción de los datos que alimentan las dimensiones y métricas. La extracción va a ser extracción de las tablas en bruto sin hacer ningún cruce con otra, se pretende tener una copia exacta de la tabla original en el área temporal de datos para posteriormente trabajar con estas tablas y no seguir consultando el origen u orígenes.
DE ESTA FORMA SI HAY DIFERENTES ORÍGENES COMO PUEDE SER UN EXCEL, UNA BBDD MONGODB O UNA BBDD REDSHIFT DE AMAZON, AL CENTRALIZAR TODOS LOS DATOS EN UN MISMO SITIO SE PODRÁ CRUZAR DATOS CON SQL DISMINUYENDO MUCHÍSIMO EL TIEMPO DE CARGA.
Bien, basta de teoría y ahora al caso práctico. Teniendo la lista anterior de las dimensiones y métricas identificadas, hay que listar de donde se puede obtener la información para las dimensiones.
Dimensiones:
- Estado del pedido:
- MySQL: estado_pedido
- id_estado_pedido
- descripcion
- nombre
- MySQL: estado_pedido
- Fecha de solicitud
- Pentaho: La dimensión fecha se va a autogenerar con Pentaho.
- Fecha de envío
- Pentaho: La dimensión fecha se va a autogenerar con Pentaho.
- Cliente
- MySQL: Cliente
- id_cliente
- nombre
- telefono
- Datawarehouse:
- Tipo cliente [vegano, carnívoro, ambos]: Se calcula dinámicamente a partir de sus compras
- Ranking [A+, A, B, C]: Se calcula dinámicamente a partir de sus compras clasificando la calidad de los clientes.
- MySQL: Cliente
- Proveedor:
- MySQL: Proveedor
- id_proveedor
- nombre
- descripcion
- MySQL: Proveedor
- Producto:
- MySQL: producto
- id_producto
- nombre
- descripcion
- id_proveedor
- pvp
- pmp
- stock
- Datawarehouse:
- stock_medio: Nivel de stock medio en los últimos 30 días
- clasificación [ A+, A, B, C ]: Se clasifica los productos en base a su facturación en los últimos 30 días.
- MySQL: producto
- Descuento Aplicado
- MySQL: descuento
- id_descuento
- nombre
- descripcion
- tipo_descuento
- Pentaho:
- categoria_descuento: En pentaho hay un paso para clasificar los descuentos en una categoría en concreto
- categoria_marketing: En pentaho hay un paso para clasificar los descuentos en una categoría en concreto
- MySQL: descuento
- Provincias
- Excel: fichero_maestras
- id_provincia: dos primeros dígitos de los códigos postales
- provincia
- latitud
- longitud
- Excel: fichero_maestras
Métricas
- Cantidad de pedidos:
- MySQL: pedido
- pedido_id
- Es un COUNT-DISTINCT de los números de pedido_id
- MySQL: pedido
- Cantidad de pedidos con incidencias
- MySQL: pedidos_incidencias
- pedido_incidencia
- Es un flag que se marca a 1 en el caso de que el pedido se encuentre en esta tabla. La suma de este campo es la cantidad de pedidos con incidencias
- MySQL: pedidos_incidencias
- Cantidad de pedidos con retrasos
- MySQL: pedidos
- fecha_estimacion
- Es un flag que se marca a 1 en el caso de que la fecha de envío es superior a la fecha de estimación. La suma de este campo es la cantidad de pedidos con retrasos.
- MySQL: pedidos
- Total facturación de pedido (suma de facturación líneas de pedido + gastos de envío + donaciones)
- MySQL: pedidos
- subtotal + gastos_envio + donaciones
- MySQL: pedidos
- Total facturación (línea de pedido sin gastos de envío y sin donaciones)
- MySQL: linea_pedidos
- pvp * unidades
- MySQL: linea_pedidos
- Facturación sin IVA (igual que la anterior pero quitando el IVA)
- MySQL: linea_pedidos
- ( pvp * ( 1 – ( iva / 100 ) ) ) * unidades
- MySQL: linea_pedidos
Una vez identificadas todas las tablas que alimentan las dimensiones y hechos se deberá programar un ETL que haga esta importación y para ellos recomiendo esta estructura de ETL.
La estructura del proceso ETL
El proceso ETL es el siguiente:

Se compone de 3 grandes procesos independiente entre ellos pero que necesita que termine uno para empezar otro. Por ejemplo, el load hace uso del contenido que hay en las tablas del datastage y este ha sido almacenado por el JOB Extract.
prepare
Incluir la lógica necesaria. Por ejemplo comprobar si existen las tablas y si no crearlas etc…
Establecer un código de proceso a partir de la fecha y hora del sistema…
Cualquier cosa que se ocurra para preparar el proceso antes de ser ejecutado.
Inicializar la variable “fecha_extract” para importar registros del origen a partir de esta fecha…

extract
Extraer toda la información de los orígenes de datos para llevarlos al datastage.
Una transformación por cada tabla, luego es más fácil de mantener el ETL e identificar posibles errores y probar
En este JOB se tiene que importar los datos de todas las tablas que se han identificado en bruto tal cual están en el origen.
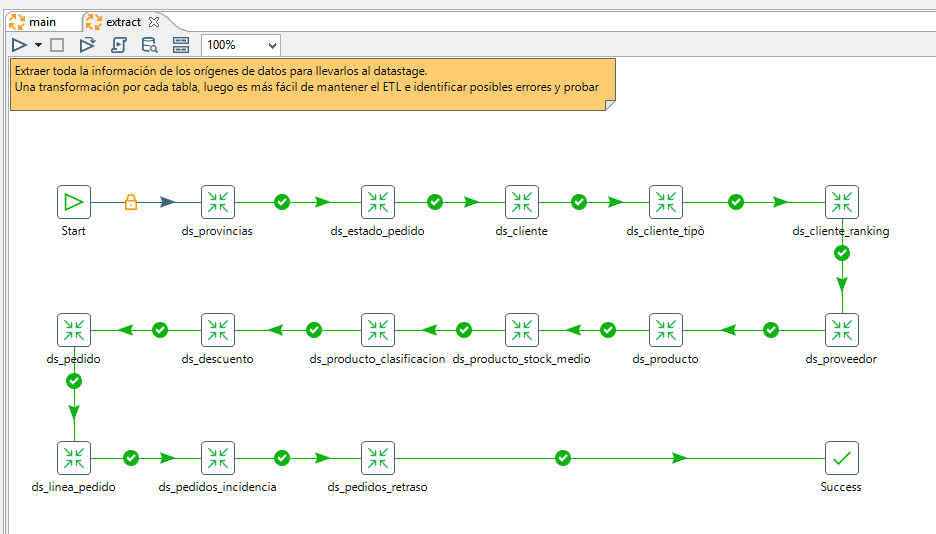
Para este proyecto base he añadido una transformación para obtener las provincias que se encuentran en la carpeta “datasource” y la importación de todas las tablas que se han identificado anteriormente del origen. Con toda esta información centralizada se es capaz de crear un modelo de estrella.
Nota: Las tablas que tienen el prefijo “ds_” hace referencia a que son tablas temporales y se encuentran en el datastage (área temporal).
load
Una vez se tienen en el área de stage toda la información centralizada en una misma BBDD ya se puede relacionar entre ella (sin importar el origen) para cargar las dimensiones y las medidas en la tabla de hechos.
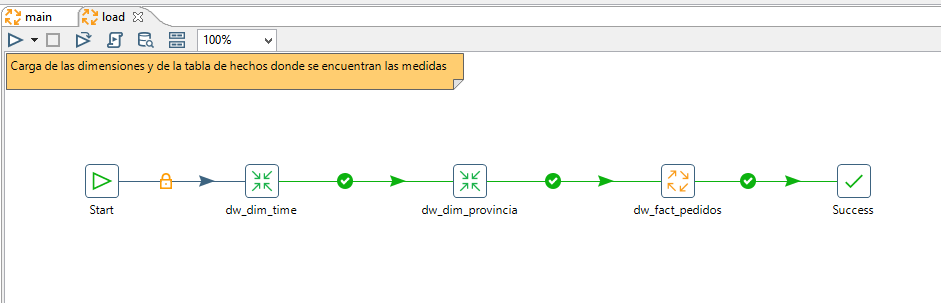
dw_fact_pedidos
Para cargar la tabla de hechos tenemos que obtener las claves subrogadas de todas las dimensiones y almacenar en esta tabla las métricas.
La estructura de esta tabla será por una parte relaciones a las dimensiones almacenando su clave subrogada y por otra los campos numéricos donde se almacenan las medidas.
Diseñar un modelo de datos analítico (modelo de estrella)
En este artículo https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/ explico porque el modelo de estrella es fundamental para un proyecto de Business Intelligence.

Bien, en el punto anterior se ha identificado los orígenes de los datos y se ha identificado las dimensiones y medidas que va a tener el modelo de estrella y este es el esquema de tablas del modelo identificado anteriormente. El proceso ETL con la información obtenida y almacenada en el datastage debe ser capaz de alimentar de datos estas tablas.
La alimentación del modelo de estrella la realiza el proceso “LOAD” a partir de toda la información obtenida en las tablas del datastage.
Un ejemplo real sobre la carga de un modelo de estrella.
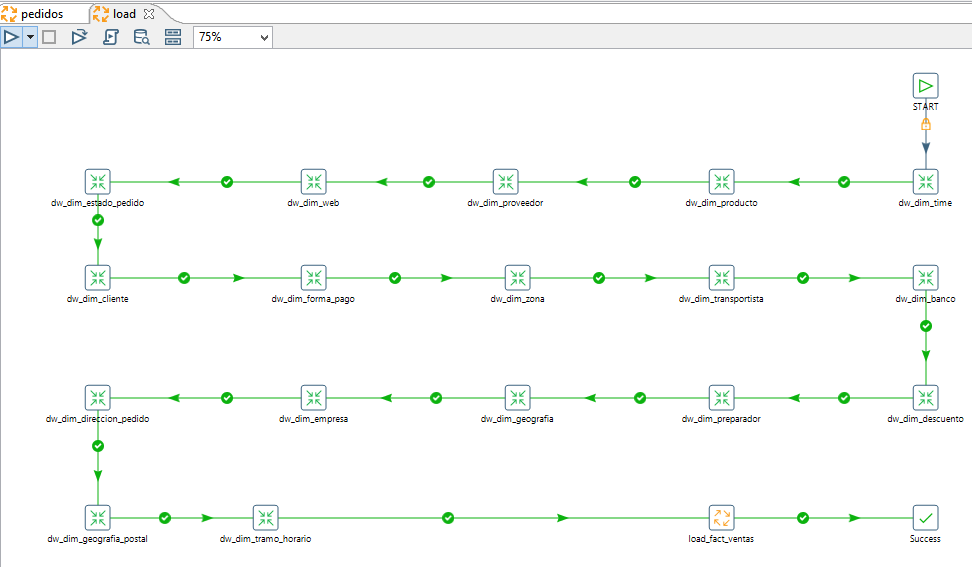
En esta imagen se observa como cada transformación carga una dimensión de un modelo de estrella y al final carga la tabla de hechos.

En esta otra imagen se carga la tabla de hechos a través de comandos SQL que es mucho más óptimo que utilizar los pasos de pentaho para obtener las claves subrogadas de las dimensiones.
La SQL que obtiene todas las claves subrogadas de las dimensiones y las métricas es esta:


Probar que la información del modelo es la misma que la del origen
Cuando se ha terminado con el desarrollo del ETL es muy pero que muy importante verificar que los datos que se encuentran en el modelo de estrella son los mismos que se encuentran en los orígenes de datos y para ello se pueden realizar estas consultas en el MySQL y en el modelo de estrella:
- Mostrar la cantidad de pedidos que se han solicitado desde el 1 de enero de 2019 hasta el 4 de abril de 2019 en el origen y modelo de estrella
- Mostrar el total de los pedidos que se encuentran en estado enviado del año 2018 en el origen y en el modelo de estrella
- Mostrar la cantidad de pedidos que van con retraso y los que son incidencia del año 2019 en el origen y en modelo de estrella
- Mostrar las unidades vendidas para los clientes que se llamen Francisco en abril del año 2019 en el origen y en el modelo de estrella.
Los resultados obtenidos en el origen y en el modelo de estrella para todas estas consultas deberían ser idénticos y si lo son entonces el modelo de estrella tiene información veraz y lista para pintar cuadros de mandos.
Contacto
Si te ha parecido útil y tienes cualquier consulta no dudes en ponerte en contacto con el correo info@datamanagement.es o bien usando el formulario de contacto que se encuentra en la página web https://datamanagement.es/contacto.php
Enlaces de interés
- Herramientas Proyecto Business Intelligence: https://datamanagement.es/2019/06/21/herramientas-proyecto-business-intelligence/
- El modelo de estrella. El pilar fundamental del Business Intelligence: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/
- Configuración de Pentaho para diferentes proyectos: https://datamanagement.es/2019/08/12/configuracion-pentaho-varios-proyectos/
- Proyecto ETL base: https://datamanagement.es/Recursos/Proyecto_base_BI.rar
[…] Desarrollo Proyecto Business Intelligence: http://datamanagement.es/blog/2019/08/18/desarrollo-proyecto-de-business-intelligence-con-pentaho/ […]