Introducción
El objetivo de este nuevo artículo es el de crear una base de datos con los datos básicos de las empresas de españa a partir de una página web haciendo web scraping con Python y PowerBI.
“Teniendo acceso a una página web, tenemos acceso a los datos”
Hace un tiempo que tengo en mente el aprender a realizar la extracción de información desde una página web y además, también quería tener una base de datos con información de empresas para otros fines y la combinación de ambas cosas han dado lugar a este artículo.
Descarga proyecto: https://datamanagement.es/Recursos/web_scraping.zip
Bien, buscando en google páginas web donde aparece información de empresas encontré varias como por ejemplo estas:
- https://www.expansion.com/directorio-empresas.html
- https://www.axesor.es/
- https://sabi.bvdinfo.com/version-20191018/home.serv?product=SabiNeo
- https://guiaempresas.universia.es/
Me decanté por utilizar la web “https://guiaempresas.universia.es/” para realizar el web scraping.

En esta página la jerarquía es la siguiente: Provincia > Población > Empresa.
El objetivo, como he comentado es tener una base de datos con todas las empresas de españa y para eso hay dos opciones:
- Ir una a una y copiar la información en un Excel: Este trabajo es muy repetitivo y se puede automatizar https://datamanagement.es/2019/09/29/automatizacion-y-optimizacion-de-procesos/
- Desarrollar un programa que sea capaz de navegar por los enlaces de la página web para obtener la información de las empresas y guardarlas en la base de datos. Este tipo de práctica se llama WEB SCRAPING
Cuando tenga la base de datos con las empresas, estas empresas las mostraré en un informe de PowerBI para poder consultar y filtrar las empresas por:
- Facturación
- Cantidad de empleados
- Provincia
- Población
- Nombre de empresa
Ahora que he realizado una introducción del artículo, a continuación voy a explicar la parte técnica de cómo he desarrollado el proceso ETL en Python para realizar el Web Scraping, además, adjuntaré el código al final del artículo para que podáis ejecutar y realizar pruebas en vuestros ordenadores
Antes de empezar
Descarga proyecto: https://datamanagement.es/Recursos/web_scraping.zip
Antes de empezar con las explicaciones, es necesario tener el sistema configurado, tener conocimientos avanzados de programación orientada a objetos y una base de programación en Python.
Qué es la programación orientada a objetos (POO)
Enlace a wikipedia: https://es.wikipedia.org/wiki/Programaci%C3%B3n_orientada_a_objetos
Explicado para “tontos” porque el mundo está lleno de gurús a los que no se les entiende nada.:
Cuando se programa hay trozos de código que se pueden reutilizar, estos trozos de código que se pueden reutilizar contienen funcionalidad específica que realiza algo en concreto como por ejemplo contar cuántos números hay en un texto, encriptar un texto o enviar un email.
Bien, estos códigos reutilizables se pueden definir como una función que cada vez que se invoca “se le da la orden de ejecutar la función” realiza la funcionalidad. Está muy bien porque se puede utilizar tantas veces queramos sin tener que volver a escribir el código pero hay un problema.
¿QUÉ PASA CUANDO ESTAMOS HACIENDO UN PROGRAMA ENORME Y TENEMOS MUCHAS FUNCIONES?
Cuando esto ocurre hay que recurrir a la programación orientada a objetos donde un objeto es una clase en la que se define una serie de atributos ( variables dentro de la clase-objeto ) y métodos ( funciones dentro de la clase-objeto ), explicado para tontos sería.
Una clase es un módulo o conjunto de funcionalidades que tienen un contexto en común. Es un paquete de funciones que están relacionadas entre sí y sirven para interactuar con los valores que se almacenan en la memoria del objeto.
Explicado con un ejemplo, se puede definir una clase/módulo persona() en la que la persona tiene una serie de funciones:
- asignarEdad (edad a asignar): Esta función asigna la edad de la persona
- obtenerEdad: Devuelve la edad de la persona
- aginarNombre (nombre a asignar): Asigna el nombre de la persona
- obtenerNombre: Devuelve el nombre de la persona
- enviarEmail ( correo para enviar email, contenido del email ): Envía un correo electrónico al correo que se le indica con el texto que recibe.
- llamarPorTelefono ( teléfono a llamar ): Llama por teléfono al teléfono que recibe.
Bien, ahora que la clase persona tiene las funciones definidas (que va a poder hacer a partir de ahora ), desde cualquier parte del código podemos crear variables del tipo persona como si fuera una variable del tipo Integer. Además, cuando tengamos la variable declarada, se podrá hacer uso de las funciones del objeto (métodos) para realizar acciones.
Nota: Un objeto es una variable del tipo de una clase/módulo con acceso a sus métodos/funciones, usando palabras técnicas, un objeto es una clase instanciada ( este tipo de expresiones son las que usan los GURÚS!!! ).
Instalación de anaconda

Anaconda es una suite con todo lo necesario para empezar a desarrollar en Python. Incluye Python, un par de IDE’S de programación y muchas librerías preinstaladas para que no invirtamos tiempo e configurar un entorno de desarrollo.
Enlace: https://www.anaconda.com/distribution/#download-section
La versión de Anaconda a descargar es la versión de Python 3.7. Esta versión es la que he utilizado para hacer la DEMO.
Instalación de MySQL
Para el desarrollo de la DEMO es necesario instalar MySQL o tener acceso a una BBDD MySQL para poder insertar en las tablas el contenido de la página web.
Creación de las tablas para el proceso
ds_empresas_scraping: En esta tabla es donde se almacena la información de las empresas
ctl_activity_process: En esta tabla se registra un log de todo lo que está sucediendo, qué URL se están procesando y sí se ha procesado OK o no.
create table ds_empresas_scraping (
url varchar(1000)
, nombre varchar(100)
, direccion varchar(1000)
, localidad varchar(500)
, provincia varchar(100)
, telefono varchar(100)
, empleados varchar(100)
, fecha_creacion varchar(100)
, cnae varchar(5000)
, coordenadas varchar(100)
, latitud varchar(50)
, longitud varchar (50)
, facturacion varchar(100)
, fecha_insert datetime
, html_response varchar(6000)
);
create table ctl_activity_process (
etl_master varchar(50),
id_process bigint(20),
url varchar(1000),
descri_activity varchar(100),
status int(11),
start_date datetime,
end_date datetime,
cant_row int(11),
fecha_desde date,
fecha_hasta date
);Instalación de PowerBI
PowerBI es una de las herramientas de visualización más usadas en todo el mundo. El diagrama de Gartner lo tiene como la herramienta de visualización TOP, por encima de Tableau, QlikView y Microstrategy.

Enlace descarga: https://powerbi.microsoft.com/es-es/desktop/
Desarrollo del proceso Web Scraping con Python
Descarga proyecto: https://datamanagement.es/Recursos/web_scraping.zip
A partir de aquí, el artículo va a ser técnico y voy a describir las clases, para que se usan, trozos de código y explicaré lo necesario para hacer funcionar el proceso en vuestros equipos.

- main.py: El proceso general a ejecutar, es el que coordina e invoca los métodos de las clases
- config.json: Este fichero contiene las variables de acceso a la base de datos
- Connection.py: Esta clase es la qué interactúa con la base de datos.
- ExtractEmpresas.py: Esta clase contiene toda la funcionalidad para realizar el web scraping de la página web https://guiaempresas.universia.es/
- LogTrazabilidad.py: Esta clase es la que registra en una tabla de control todo lo que va sucediendo.
- UserAgentRandom.py: Esta clase es la responsable de recibir una URL y devolver el contenido HTML en formato String.
config.json:
Este fichero contiene las variables de acceso a la base de datos
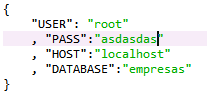
Este fichero contiene las variables de acceso a la base de datos y nada más.
Connection.py:
Clase para conectar Python con MySQL y ejecutar Querys.

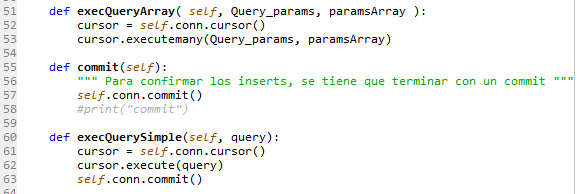
En el momento de crear esta clase es necesario enviarle los valores de conexión, una vez creado el objeto conexión, ya se podrá realizar querys contra la BBDD.
LogTrazabilidad.py:
Esta clase es la que registra en una tabla de control todo lo que va sucediendo.


Dentro del main y de la clase ExtractEmpresas se llaman a los métodos para ir registrando en la tabla de log todo lo que va sucediendo
UserAgentRandom.py:
Esta clase es la responsable de recibir una URL y devolver el contenido HTML en formato String.
Hay un problema con el servidor web donde realizamos el web scraping, tienen una limitación de peticiones HTTP por lo que es necesario realizar por cada petición HTTP cambiar el User-Agent y utilizar un proxy diferente.
En cada petición HTTP le envíamos un header con un User-Agent diferente, eso es que por cada petición web que hacemos al servidor le estamos indicando que somos un navegador distinto para que no nos bloqueé. Además, en cada petición hacemos uso de un proxy distinto.
Aún así, el mecanismo anti web scraping que tienen se activa, es un captcha de google que que validar cuando se activa si no no tendremos acceso a la info de la empresa.
Por otra parte, fuerzo a realizar cada consulta HTTP entre 3s y 5s para añadir más dificultad al servidor de ser detectados como scrapeador.

Dentro de la carpeta PROXIS hay un fichero con una lista de proxies diferente en formato ip:puerto.
Dentro de la carpeta USERAGENT_LIST hay ficheros con los diferentes User-Agent que actualmente para hacer peticiones con los diferentes User-Agent en cada petición HTTP.
Es necesario configurar las rutas “ruta” y “ruta_proxis” para poder guardar en la lista los valores de los ficheros.



El método “RequestURL” es el responsable de recibir una URL y devolver el contenido HTML en formato String. Internamente por cada petición hace uso de un User-Agent diferente y un Proxy diferente. Además, espera entre 3s y 5s para realizar una petición para no saturar al servidor. Un humano es incapaz de hacer 1000 peticiones en 1s por lo que tantas peticiones en un periodo corto de tiempo es señal de que intenta hackear
ExtractEmpresas.py:
Esta clase contiene toda la funcionalidad para realizar el web scraping de la página web https://guiaempresas.universia.es/
En la clase tengo puesto dos filtros, el enlace de la provincia y el de la localidad. Tengo puesto estos filtros porque cuando se realiza muchas peticiones web desde la misma IP, el mecanismo anti scraping que tienen se activa y bloquea las conexiones usando un Captcha.



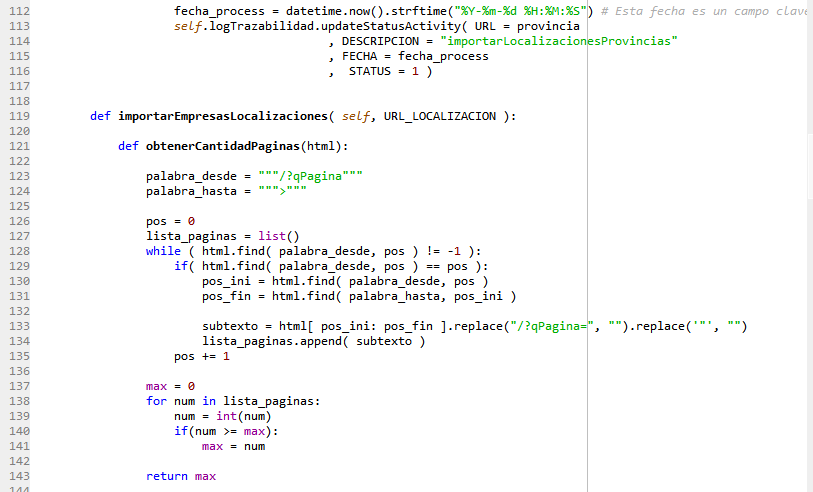






Esta clase para hacer uso de ella en el constructor es obligado enviar por parámetro 3 objetos:
- Connection
- LogTrazabilidad
- UserAgentRandom
Estos 3 objetos son necesarios para el correcto funcionamiento de la clase. Una vez creado el Objeto de la clase “ExtractEmpresas” sólo necesitamos invocar/ejecutar el método “leerEmpresas” y ya el solo funcionará.
Para extraer la info del HTML desarrollé una función clave que obtiene el contenido que hay entre dos cadenas de texto.

Esta función lo que hace es recibir el HTML, la palabra desde donde quiero obtener el valor, y donde acaba y devuelve el contenido que hay entre esas dos palabras
Ejemplo:


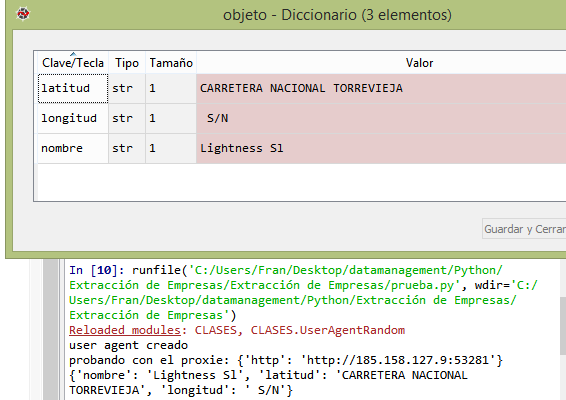
main.py:
El proceso general a ejecutar, es el que coordina e invoca los métodos de las clases

Este fichero carga el config.json para obtener las variables de conexión y luego instancia/crea los objetos para tener conexión con la base de datos, para poder registrar el log, para poder descargarnos el contenido web en formato string y para poder hacer la extracción de las empresas.
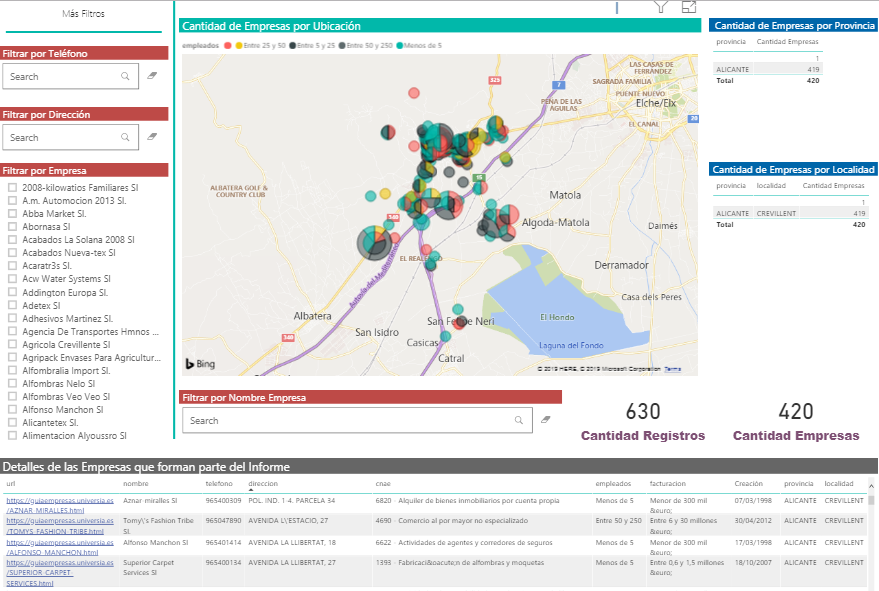
Tabla de empresas
Cuando se ejecuta el proceso, el solo va extrayendo los datos e insertándolos en esta tabla.
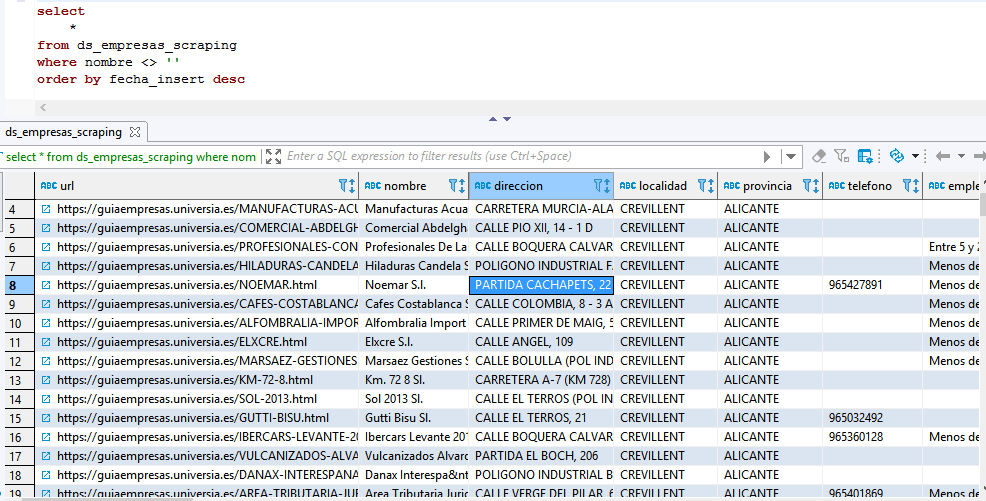
Como se observa, almaceno la URL original, el nombre de la empresa, dirección, población… y la respuesta HTML que devuelve el servidor web.
La tabla ya está lista para ser consultada.
Consultar las empresas con PowerBI
El fichero “Empresas Python.pbix” tiene los datos de la tabla. He diseñado un pequeño informe con PowerBI para consultar estos datos y añadir filtros.
Voy a mostrar los pasos básicos.
- Importación de los datos
En primer lugar es necesario realizar la importación de los datos de la tabla donde el proceso de Python está guardando la información de las empresas.
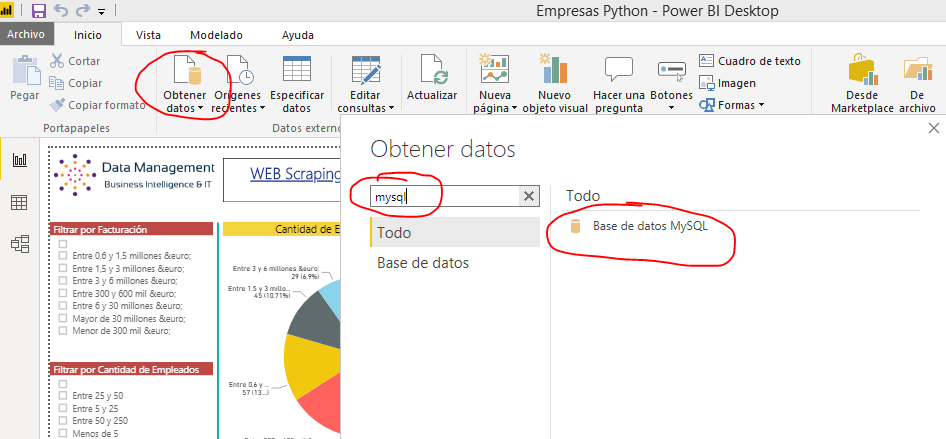
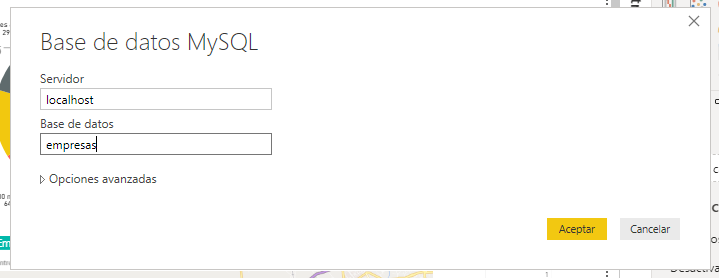

- Definición de métricas
Un “truco” de powerBI es la creación de una tabla vacía para guardar en ella todas las métricas que programemos. De esta forma las métricas estarán juntas en un mismo lugar.

La métrica “Cantidad Empresas” es un distinct Count de los nombres de empresa ya que por algún motivo esta podría repetirse. Además, puede venir vacío este campo por no poderse importar el contenido y solo cuenta los campos distintos de nulo.

La métrica “Cantidad Registros” cuenta la cantidad de registros que hay en la tabla que es diferente a la cantidad de empresas. De esta forma podemos saber que porcentaje de registros se ha podido obtener los datos de las empresas y cual no.
- Diseñar informe
El informe que he diseñado ha sido este, podríais diseñar otros informes con los mismos datos.


Contacto
Si te ha parecido útil y tienes cualquier consulta no dudes en ponerte en contacto con el correo info@datamanagement.es o bien usando el formulario de contacto que se encuentra en la página web https://datamanagement.es/contacto.php
Enlaces de interés
- Descarga proyecto: https://datamanagement.es/Recursos/web_scraping.zip
- Proceso ETL con Python desde cero y paso a paso: https://datamanagement.es/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/
- Herramientas Proyecto Business Intelligence: https://datamanagement.es/2019/06/21/herramientas-proyecto-business-intelligence/
- El modelo de estrella. El pilar fundamental del Business Intelligence: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/
- Configuración de Pentaho para diferentes proyectos: https://datamanagement.es/2019/08/12/configuracion-pentaho-varios-proyectos/
[…] Hace 4 años escribí este artículo: https://datamanagement.es/2019/10/26/web-scraping-de-empresas-con-etl-en-python-y-powerbi/ […]