¿Qué es el web scraping? ¿Qué se puede obtener con él? ¿Por qué es interesante aplicarlo en tu negocio? ¿Qué beneficios podría aportar? A continuación se muestra un ejemplo real.
Qué es el web scraping
El web scraping es la técnica para extraer datos de páginas web mediante programación o software especializado.
Esto se puede lograr con diversas herramientas de low code, utilizando diferentes lenguajes de programación y frameworks diseñados para este propósito.
¿Cómo llevo a cabo el web scraping? Utilizo el lenguaje de programación Python sin ningún framework. Hago uso de la librería «requests» de Python para acceder a las páginas web y de «pandas» para convertir las listas en dataframes.
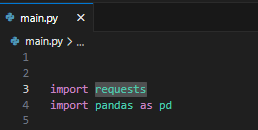
Con estas 2 librerías y programación se puede empezar ya a extraer información.
A continuación explico cómo se puede obtener la información y ejemplos de utilidad que podrías darle a tu negocio
¿Qué se puede obtener con él Web Scraping?
Se puede obtener, por ejemplo, el listado de productos con su información (título, SKU, precio, descripción, si se puede comprar o no, URL, imágenes) y exportarlo a un archivo Excel, CSV u hojas de cálculo.
Cuando accedes a una página web, el servidor web devuelve contenido HTML, Javascript y CSS. En el contenido HTML está la web maquetada con referencias a las imágenes, con los valores de los formularios, con el código javascript, con los enlaces, videos… está todo lo necesario para “cogerlo” y utilizarlo.
Aquí un ejemplo de una página web y su HTML
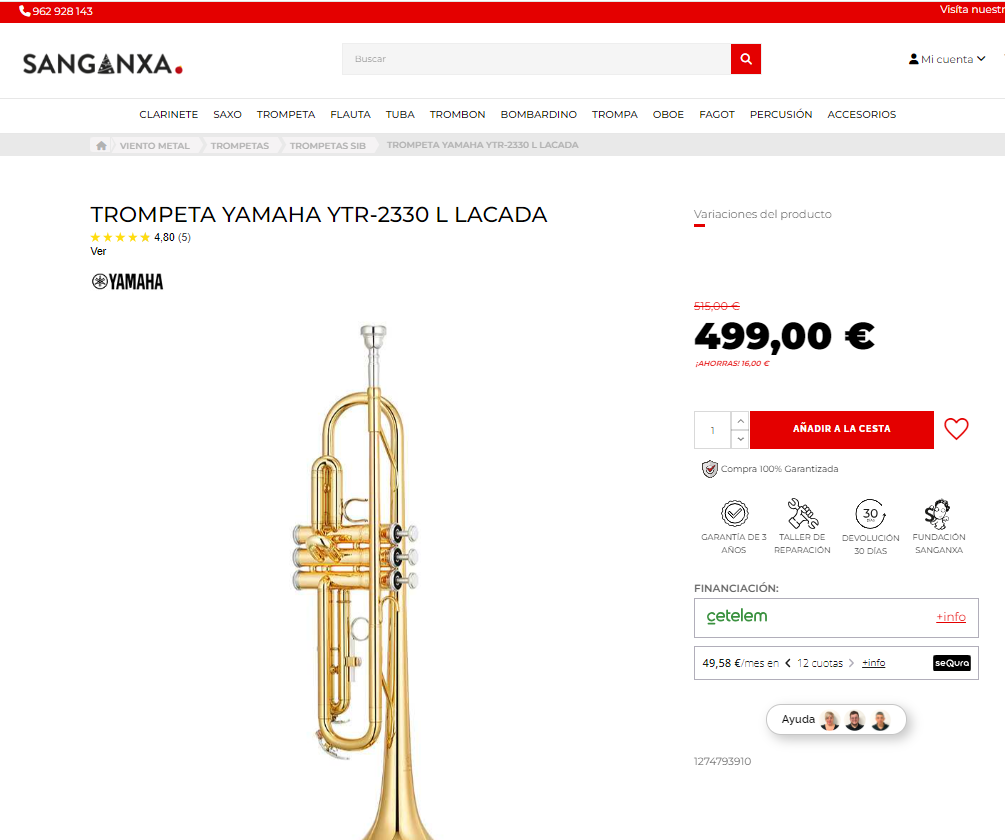
La página web vista desde el navegador
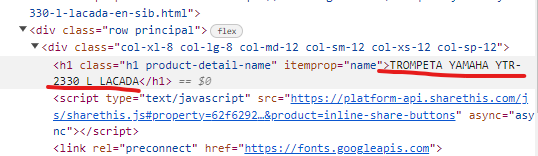
El título del producto en HTML
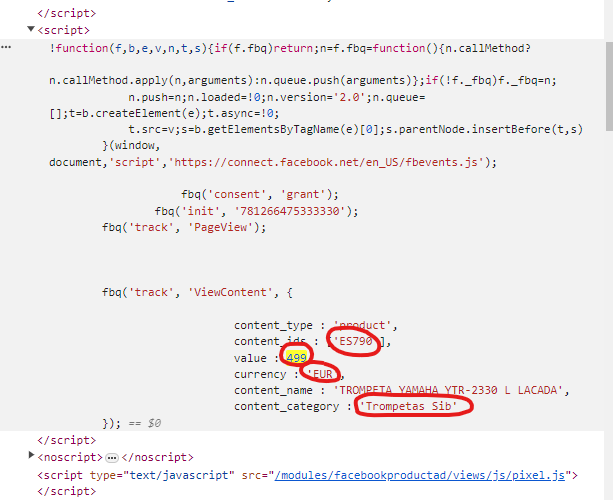
El precio, el ID del producto, la categoría… en HTML
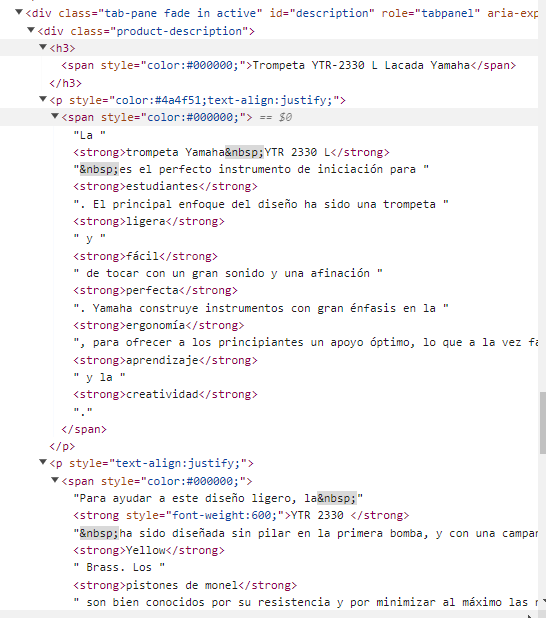
Descripción del producto en HTML

Las imágenes del producto
Hace 4 años escribí este artículo: https://datamanagement.es/2019/10/26/web-scraping-de-empresas-con-etl-en-python-y-powerbi/
¿Por qué es interesante aplicarlo en tu negocio?
Con la explicación anterior, lo más seguro es que tú, como lector, hayas encontrado muchas ideas para poder aplicarlo en tu empresa o que esto te resuelva muchos problemas que hasta ahora has sido incapaz de resolver cómo integrarte con una plataforma sin acceso a una API.
A continuación, doy un par de ideas y estoy seguro de que más de una de ellas podría resolver más de un problema para ti.
Utilizo la herramienta [XXX] para obtener leads, pero lamentablemente, esta herramienta no cuenta con una API, lo que hace imposible integrarse con ella.
Mi cliente utiliza una plataforma web para obtener leads de personas interesadas en realizar una reforma. Hasta ahora, diariamente, ingresaba a la plataforma, revisaba los anuncios y recopilaba manualmente la información para luego insertarla en su CRM.
Dado que la plataforma no cuenta con una API y el acceso a su base de datos no está disponible, se implementó un proceso de web scraping para el cliente. Este proceso se ejecuta tres veces al día y sigue la siguiente metodología:
- Hace login en la web con su usuario y contraseña
- Accede a los últimos leads obtenidos
- Combina la información vieja con la nueva en un spreadsheets
- Se inserta en el CRM de forma automática
Como agencia de marketing, necesito descargar diariamente las ventas de Shopify, WooCommerce, PrestaShop, entre otros. Sin embargo, no tengo acceso a una API ni a las bases de datos y necesito la información diariamente en un Spreadsheets.
Mi cliente requería acceder a la información de un ecommerce, del cual no disponía de acceso a la base de datos ni a ninguna API. Sin embargo, contaba con acceso al backoffice de PrestaShop.
El objetivo del proyecto era sencillo: descargar un archivo CSV privado que PrestaShop genera automáticamente tres veces al día. Para lograrlo, debía seguir los siguientes pasos:
- login al backoffice
- navegar por las opciones de la web
- descargarse el CSV.
En mi ecommerce, quiero establecer automáticamente los precios de N productos. Para lograrlo, me gustaría conocer los precios de la competencia y mantener siempre un margen del 2% por debajo de sus precios. Además, deseo que este proceso sea automático y se actualice tres veces al día.
Presento esta idea, ya que hasta la fecha no he desarrollado algo para cumplir con este objetivo. El siguiente punto describe cómo se puede lograr la realización de esta tarea.
Estoy a punto de lanzar un nuevo ecommerce y ya cuento con un proveedor. Actualmente, el catálogo completo de productos se encuentra en una plataforma, pero lamentablemente no dispongo de acceso a la base de datos del proveedor ni a su API. Mi objetivo es cargar automáticamente 2000 productos en mi ecommerce sin tener acceso directo a dicha información. ¿Cómo puedo llevar a cabo este proceso de manera eficiente?
Mi cliente, quien está dando sus primeros pasos en el mundo del ecommerce, tiene la intención de cargar todo el catálogo de productos de la web https://www.sanganxa.com/ en su propia página web. Dado que no cuenta con una opción de carga masiva, se requiere una solución que permita mantener sincronizada la disponibilidad de compra y los precios de cada producto.
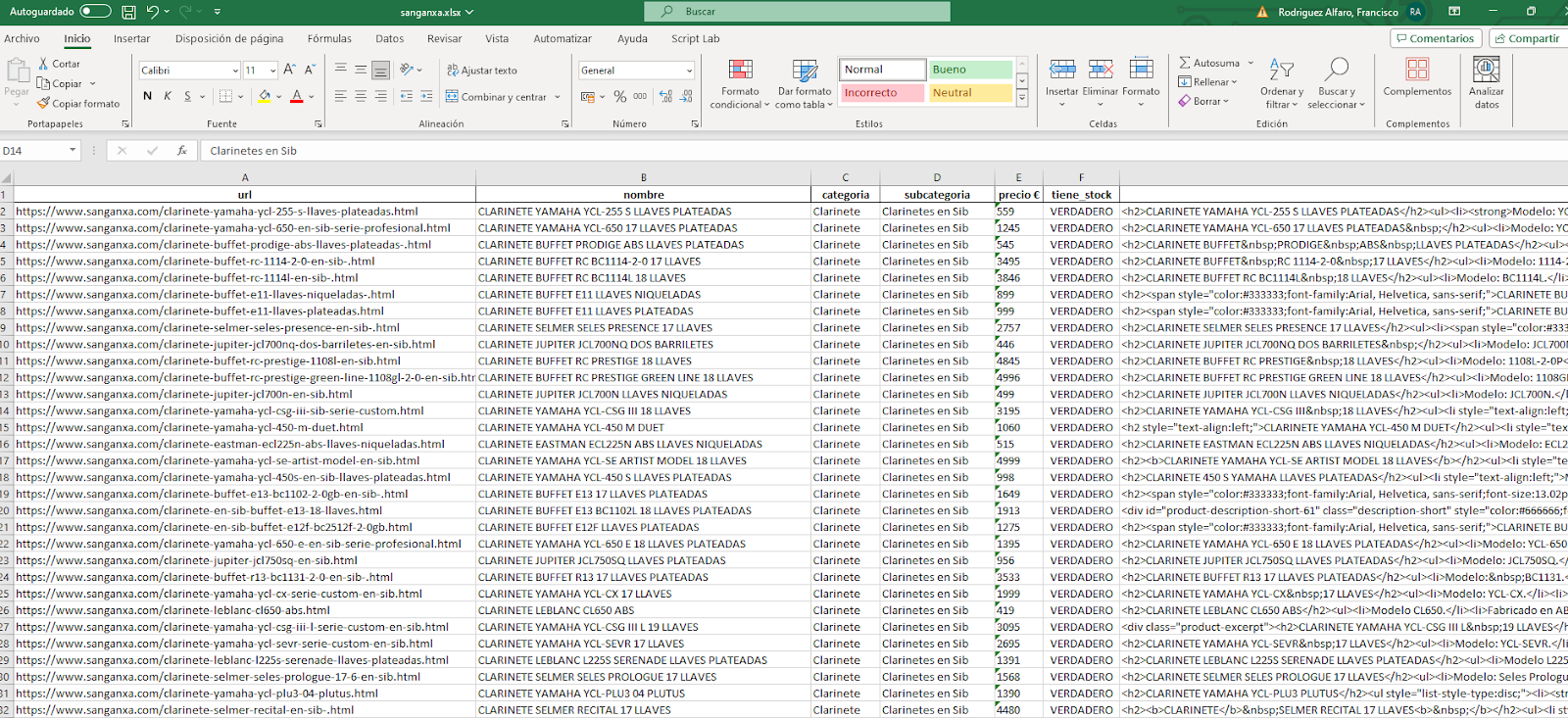
En una primera fase del proceso, se ha desarrollado la descarga de todo el catálogo de productos en un archivo Excel. El objetivo es cargar este catálogo en su backoffice con un solo clic, facilitando así la integración y actualización automática de la información, especialmente en casos de cambios en la disponibilidad o precios en la web de origen.
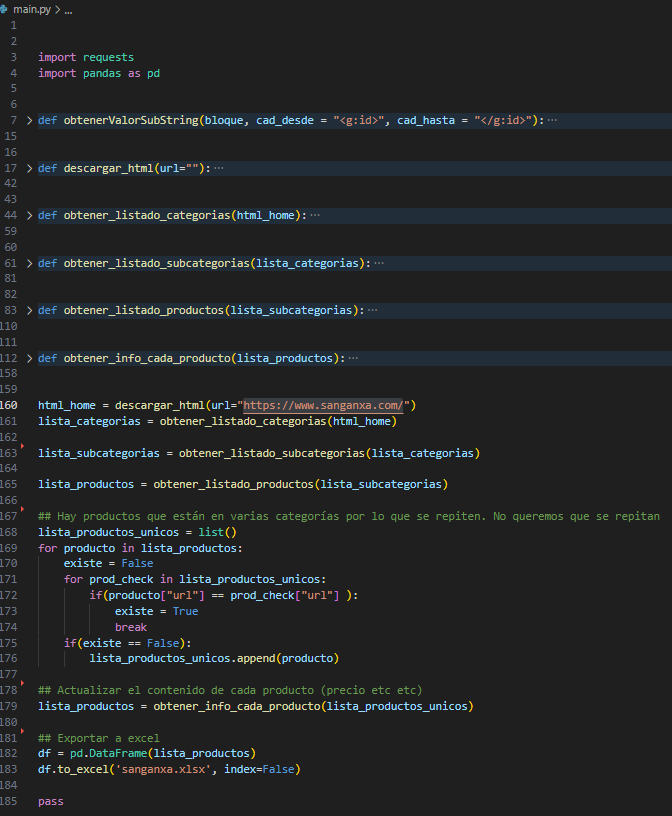
A continuación unos detalles sobre el proceso desarrollado con Python.
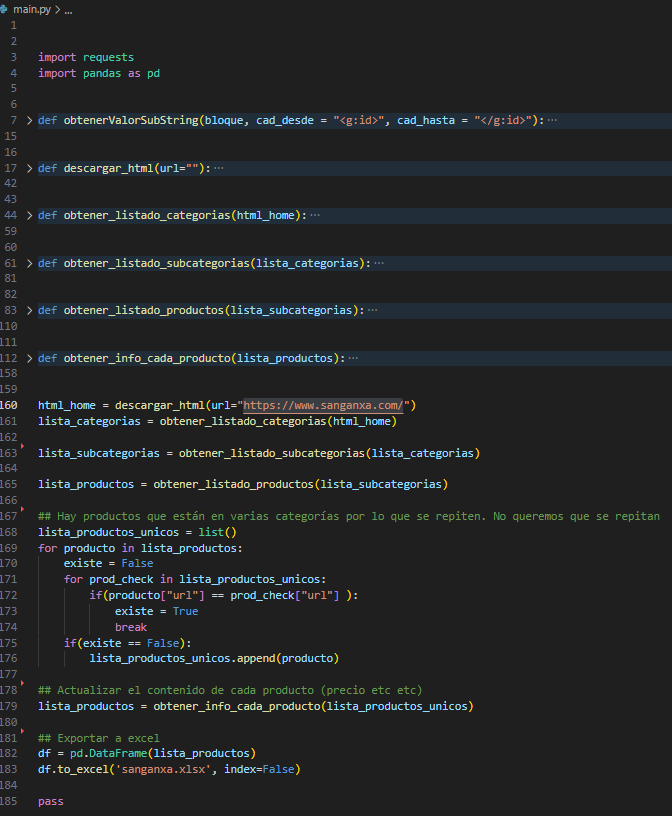
Como se puede observar en el código, el proceso comienza con la descarga de las categorías de productos. Posteriormente, para cada categoría, se procede a la descarga de sus subcategorías y, a su vez, para estas subcategorías se obtiene la lista de productos correspondiente.
Una vez se han recopilado todos los productos, el proceso continúa con la descarga de los detalles individuales de cada producto, tales como el precio, título, videos, descripción, SKU, ID, entre otros. Este enfoque permite obtener una visión completa y detallada de la información de cada producto para su posterior integración en el sistema.
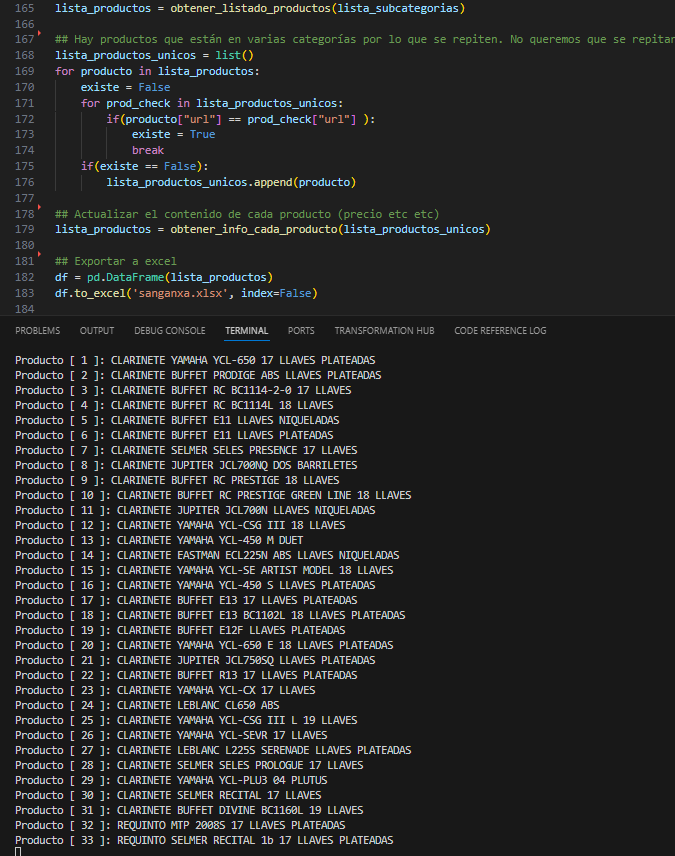
Ejecución del proceso
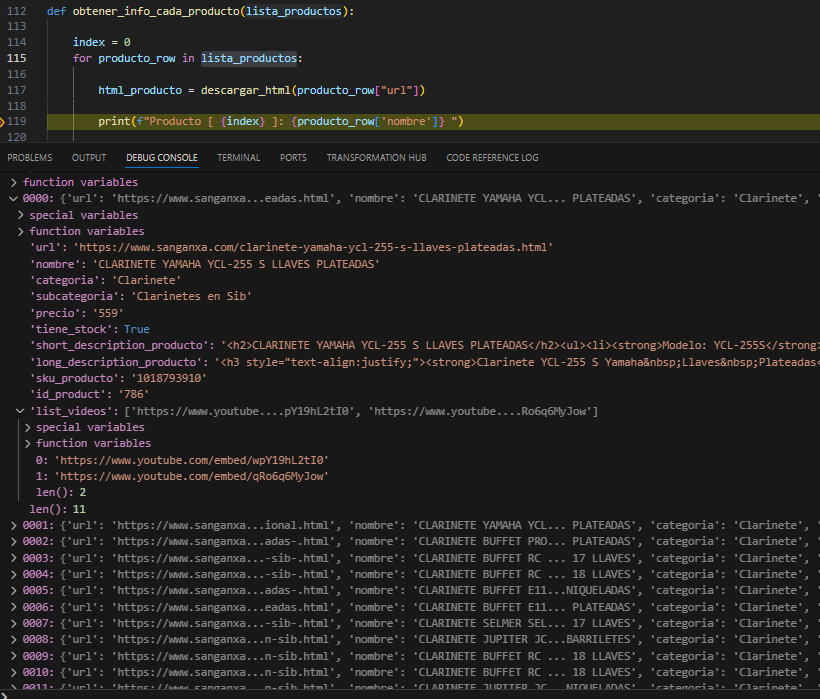
Debug del proceso y comprobación de qué descarga la info bien
Cuando todo el proceso está completo, el resultado es un archivo Excel que está listo para ser utilizado. Este archivo Excel se convierte en la base sobre la cual se puede desarrollar un proceso ETL (Extract, Transform, Load), web scraping, o cualquier proceso de integración de datos.
Este enfoque permite trabajar de manera eficiente con la información recopilada y facilita su incorporación en los sistemas y herramientas pertinentes.
¿Qué beneficios podría aportar?
Con todo lo explicado anteriormente, los beneficios que el web scraping puede aportar a tu negocio se pueden resumir en:
- Integración con plataformas que no tengan API.
- Integración con backoffices de herramientas de terceros.
- Automatización de procesos.
- Migración de datos.
- Integración de datos entre diferentes plataformas que no son propietarias.
- Resolver cualquier problema de los 1000 que diariamente hay en las empresas