Introducción
Python es un lenguaje de programación que cada vez se utiliza más por las empresas y programadores que trabajan con datos (Business Intelligence, Integración de datos, Data Science, Machine Learning, Big Data…). El motivo de que cada vez cobra más importancia en su uso es en la gran cantidad de librerías existentes para realizar prácticamente todo y más aún si el objetivo es trabajar y gestionar datos, también por lo optimizado que está Python respecto a JAVA.
Para redactar este artículo he desarrollado un proceso ETL con Python desde cero en el que voy a explicar paso a paso todo lo utilizado y porqué. Para desarrollar el proceso me he inventado un objetivo y así dar sentido al desarrollo.
Objetivo
Descarga del proyecto: https://datamanagement.es/Recursos/python_parserXML.zip
Uno de nuestros clientes nos proporciona información sobre pedidos en formato XML porque no nos puede dar acceso a la Base de datos, esta es una práctica muy común ya que dar acceso de información sensible a terceros es un poco peligroso.
Bien, para acceder a los datos nos ofrecen la siguiente URL: https://datamanagement.es/Recursos/pedidos.rar
El contenido de este fichero son 3 ficheros .XML y hay que desarrollar un proceso en python que realice lo siguiente:
- Descargar el rar
- Descomprimir el contenido en una carpeta
- Parsear los ficheros XML e insertar los datos en una base de datos
Además de todo esto, hay que registrar en una tabla de control todo lo que va sucediendo para poder consultar qué ficheros se han procesado, sí se han procesado bien, cuánto han tardado y cuando se han procesado.
Preparación entorno
Instalación de anaconda

Anaconda es una suite con todo lo necesario para empezar a desarrollar en Python. Incluye Python, un par de IDE’S de programación y muchas librerías preinstaladas para que no invirtamos tiempo e configurar un entorno de desarrollo.
Enlace: https://www.anaconda.com/distribution/#download-section
La versión de Anaconda a descargar es la versión de Python 3.7. Esta versión es la que he utilizado para hacer la DEMO.
Instalación de MySQL
Para el desarrollo de la DEMO es necesario instalar MySQL o tener acceso a una BBDD MySQL para poder insertar en las tablas el contenido de los ficheros XML.
Creación de las tablas en MySQL
Al final del documento adjunto las DDL ( creación de tablas ) para crear las tablas.
La información de los XML las tenemos que llevar a unas tablas de la BBDD y son las siguientes
- ctl_activity_process: En esta tabla se guarda el log de todo lo que va sucediendo en el código.
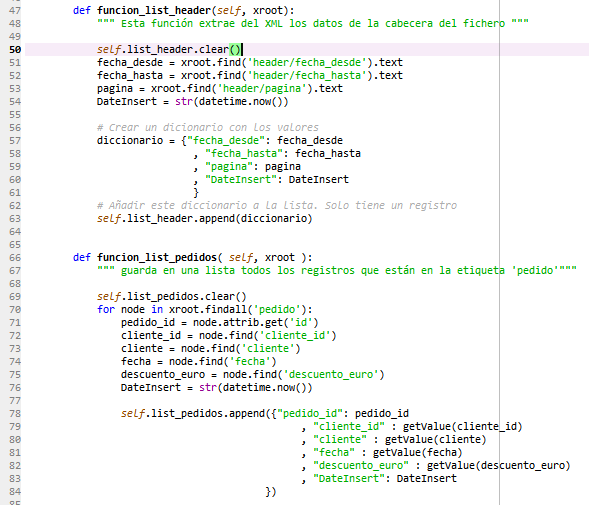
- header: Aquí se guarda la información del XML qué está dentro de la etiqueta header
- pedidos: Aquí se guarda la información de las cabeceras de los pedidos
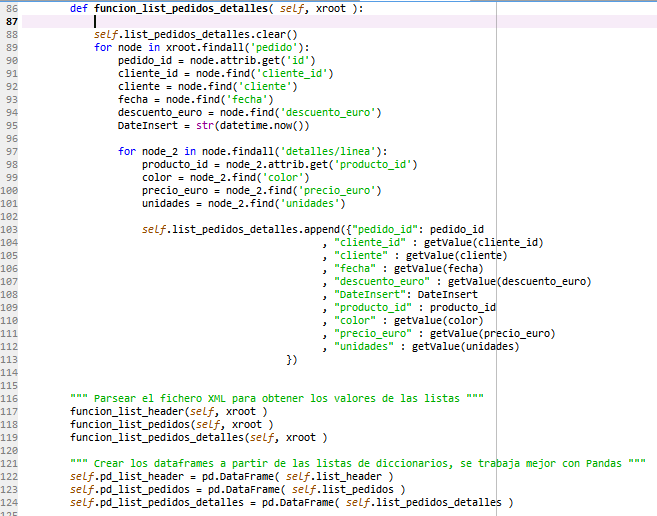
- pedidos_detalles: Aquí se guarda las líneas de pedido de cada pedido.
Estructura de los ficheros XML

Viendo la estructura del fichero XML, podemos extraer 3 tipos de información.
- Los datos qué hay dentro de la etiqueta header parece ser qué definen información del fichero. Estos datos los vamos a guardar en una tabla en BBDD
- Los datos de las cabeceras de pedidos, estos datos se encuentran dentro de la etiqueta “pedido” y los llevaremos a una tabla.
- Los datos de detalles de pedidos se encuentran dentro de la etiqueta “pedido/detalles/linea” y los llevaremos a otra tabla.
Desarrollo del proceso
Descarga del proyecto: https://datamanagement.es/Recursos/python_parserXML.zip
Antes de empezar con el desarrollo he de decir que hay que tener conocimientos en programación orientada a objetos POO en cualquier lenguaje ya que he definido clases para encapsular la lógica en pequeños paquetes/módulos/clases.
La estructura del proyecto es la siguiente.

config.json
En este fichero se encuentran todas las variables de configuración del proceso.

Para hacer uso del proceso hay que configurar los valores de las variables. Hay que definir el acceso a las BBDD y cambiar las rutas absolutas de las variables RUTA_XML y RUTA_DOWNLOAD.
- RUTA_DOWNLOAD: Aquí definimos la ruta donde queremos que guarde el fichero descargado de la URL_PEDIDOS_DOWNLOAD
- RUTA_XML: En esta ruta se va a descomprimir el contenido del fichero descargado de la RUTA_DOWNLOAD
Connection.py
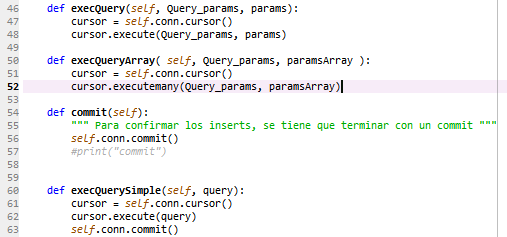
Este fichero es el responsable de la comunicación con la BBDD.
Tiene los métodos para ejecutar comandos SQL de inserción y actualización de registros que se generan en otras partes del código.

gestionArchivos.py
Esta clase es la responsable de la gestión de los archivos. Se responsabiliza de realizar la descarga del fichero rar que está en esta URL https://datamanagement.es//Recursos/pedidos.rar, descomprimir el contenido en una carpeta y luego obtener una lista de los ficheros que tienen la extensión .xml o .XML para posteriormente con otra clase realizar el parseo de los ficheros XML.
Para hacer funcionar esta clase es necesario instalar en Python los siguientes módulos.
- pip install pyunpack
- pip install patool


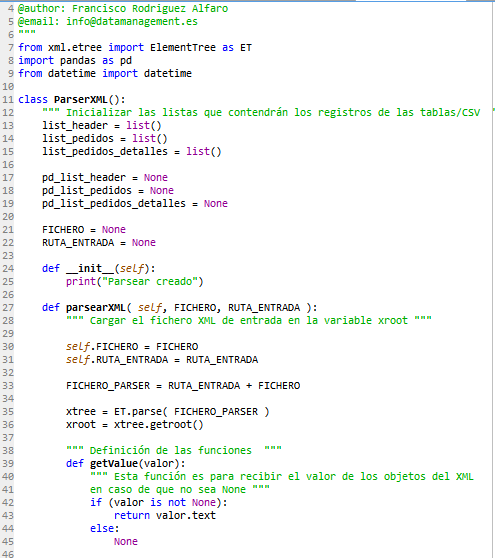
ParserXML.py
Este fichero es el responsable de parsear el XML que se le indica. Obtiene toda la información del fichero, de los pedidos y de los detalles de los pedidos que están dentro de todos los ficheros XML descomprimidos.
Para parsear un XML hay que indicarle qué fichero tiene que parsear y después “ordenar” que inserte los registros en la BBDD invocando al método “insertRowsToBBDD”, para invocar a este método hay que pasarle como argumento la conexión a la BBDD porque hace uso de la conexión para insertar los registros en las tablas.

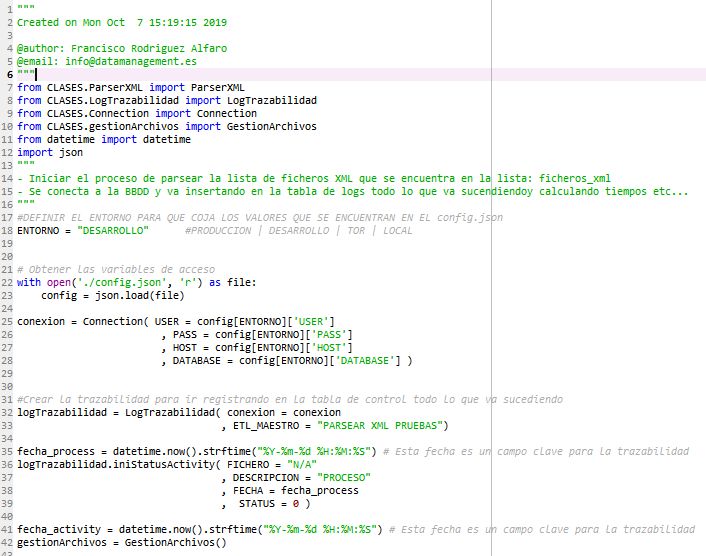
LogTrazabilidad.py
Este fichero es el responsable de ir registrando en una tabla de control todo lo qué sucede dentro del código. Para que pueda insertar en la tabla de control tiene que recibir por argumento la conexión a la BBDD.
Con el método iniStatusActivity lo que hace es insertar un nuevo registro con el nombre del fichero, descripción, fecha y status recibido.
Con el método updateStatusActivity lo que hace es actualizar el registro anteriormente insertado con la fecha fin y el estado.
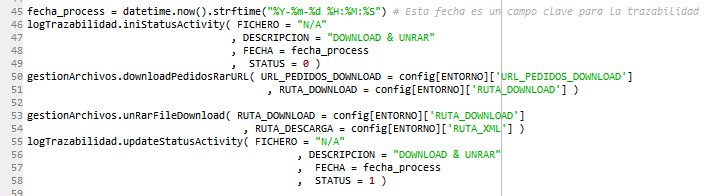
Un ejemplo de uso es el siguiente:

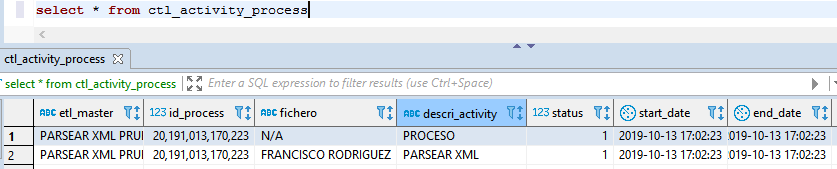
Para este ejemplo, el resultado en BBDD es el siguiente
Y para una ejecución real es el siguiente

Se puede ver que para descargar el .rar el proceso ha tardado 1s y luego ha tardado menos de un segundo en copiar la información a la BBDD.

main.py
Es el fichero a ejecutar y es el que “orquesta” el proceso. Crea la conexión a la BBDD, “ordena” a descargar los ficheros y descomprimir y “ordena” a parsear los ficheros descomprimidos.
Al tener la funcionalidad separada en módulos es mucho más fácil de entender, el código se hace más limpio y reutilizamos mucho código.

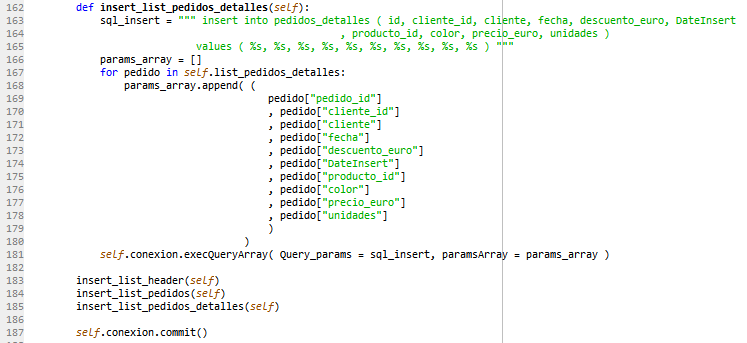
DDL Tablas
CREATE TABLE ctl_activity_process (
etl_master varchar(50),
id_process bigint(20),
fichero varchar(100),
descri_activity varchar(100),
status int(11),
start_date datetime,
end_date datetime,
cant_row int(11),
fecha_desde date,
fecha_hasta date
);
create table header (
pagina varchar(100)
, fecha_desde date
, fecha_hasta date
, DateInsert datetime
);
create table pedidos (
id integer
, cliente_id integer
, cliente varchar(100)
, fecha datetime
, descuento_euro float
, DateInsert datetime
);
create table pedidos_detalles (
id integer
, cliente_id integer
, cliente varchar(100)
, fecha datetime
, descuento_euro float
, DateInsert datetime
, producto_id integer
, color varchar(50)
, precio_euro float
, unidades integer
);Contacto
Descarga del proyecto: https://datamanagement.es/Recursos/python_parserXML.zip
Si te ha parecido útil y tienes cualquier consulta no dudes en ponerte en contacto con el correo info@datamanagement.es o bien usando el formulario de contacto que se encuentra en la página web https://datamanagement.es/contacto.php
Enlaces de interés
- Herramientas Proyecto Business Intelligence: https:https://datamanagement.es/2019/06/21/herramientas-proyecto-business-intelligence/
- El modelo de estrella. El pilar fundamental del Business Intelligence: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/
- Configuración de Pentaho para diferentes proyectos: https://datamanagement.es/2019/08/12/configuracion-pentaho-varios-proyectos/
[…] https://datamanagement.es/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/ […]
[…] Proceso ETL con Python desde cero y paso a paso: http://datamanagement.es/blog/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/ […]
[…] Enlace a otro artículo: http://datamanagement.es/blog/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/ […]
[…] Proceso ETL con Python desde cero y paso a paso: http://datamanagement.es/blog/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/ […]