Original Post: https://datamanagement.es/2019/06/27/business-intelligence-modelo-estrella/
In the Business Intelligence (BI) world having a data warehouse to have all the information obtained from different sources in the same database is really important. Also, this information must be normalized and that is why I am writing this article about star schemas, every data warehouse’s building block, but not the only one.
Before starting to define the star schema I am going to speak very briefly about Kimball and Inmon and what is proposed by each one of them, then, I will explain the star schema and its rival, the snowflake schema.
Kimball
Link: https://blog.bi-geek.com/arquitectura-el-enfoque-de-ralph-kimball/
In order to design a data warehouse you have to know the business very well, but what if you do not know it or you work for a consulting agency? Do we have to spend a lot of time getting to know, understanding and mastering all the business processes in order to design the data warehouse later? The answer is NOT NECESSARILY.
The philosophy proposed by Kimball is the ‘bottom-up’, which is also followed in software development and consists in starting by simple tasks and as the project progresses it evolves.
If we think about it, this philosophy comes from basic needs and it creates a first schema which will respond only to a few company users, so the data warehouse in this moment is an equivalent to a data mart. When this data mart is working perfectly, other schemas which meet the needs of other departments keep being developed and then we could be talking about a data warehouse.
The key about having all the schemas in the same data warehouse is that the dimensions are shared between the schemas.
The structure of this data warehouse could be big, denormalized tables with all the information, star or snowflake schemas.
As I see it, the star schema is the best one thanks to its maintainability, dimensions reuse and lower amount of foreign keys in the fact tables.
Inmon
Link: https://blog.bi-geek.com/arquitectura-enfoque-de-william-h-inmon/
Inmon proposes having different data marts in a data warehouse, practically speaking this means that each data schema or fact table has its own dimensions, being possible to have the dimension CLIENT, for example, duplicated in different data marts. Each department in the company would have their own data mart with its data.
Inmon requires having a normalised data structure until the third normal form 3NF as well (most web applications are normalised in this form and they are database fundamentals).
3NF: https://es.wikipedia.org/wiki/Tercera_forma_normal
The structure required by Inmon is that of a snowflake (not a star one) which penalizes performance for using a large amount of joins. My question is: if it requires having a snowflake schema, why not query the database directly? Performance would be very similar.
My experience using Kimball
In my experience, when I started developing the data warehouse in Planeta Huerto I did not know the business and, at the same time the data warehouse was being built, my colleagues applied for data and reports of a database I did not know. Thanks to these reports which I made day by day and to the help of the developers who explained to me the BBDD structure I was able to understand how it was structured.
I followed the Kimball philosophy and I worked with a ‘bottom-up’ strategy, as new requirements came I added new metrics and foreign keys to the dimensions. I also generated new schemas, managing to have schemas which met the departments’ needs:
- Marketing
- Product
- Finance
- Stock
- Overview
From my point of view, using kimball is working quickly and effectively, a requirement can change at any time. If I had used Inmon I think that after 8 months I would still be doing an analysis or just unemployed.
Star schema
As I regard, star schema is the most practical when designing a data warehouse, it is the one I use daily for the following reasons:
- I share dimensions between different fact tables
- I update a dimension and it appears in every schema and report
- I get rid of the snowflake complexity, I have dimensions with many foreign keys (many duplicate values) but having it like that is worth it.
- You have far fewer tables but bigger and with more information. This is good because in the product dimension you know you will find the brand, category, family, provider… These data in a snowflake schema would be independent dimensions.
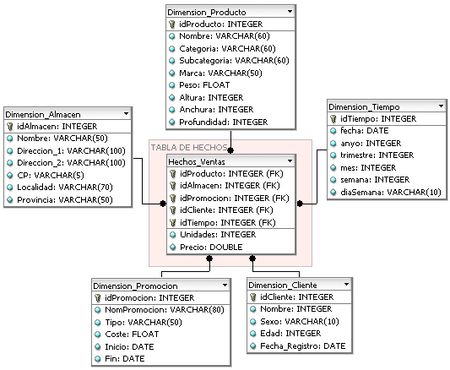
In this image we can see how if the dimension ‘Vehículo’ used the snowflake schema the keys and category would be separate tables making it much more complex to submit a query.
Snowflake schema
In an ideal world this schema would be the ideal one, but it is not,by designing a snowflake schema we would have a normalised data warehouse in the 3NF. That is how all transactional databases work, such as the e-commerce, etc. But I do not think this necessary for an analytic system because of the following reasons:
- Having many tables forces us to making a lot of joins
- Every join slows down a query very much. For tables with 100 entries we do not have to worry but with a 20 million entries table we have time to give many likes in tinder.
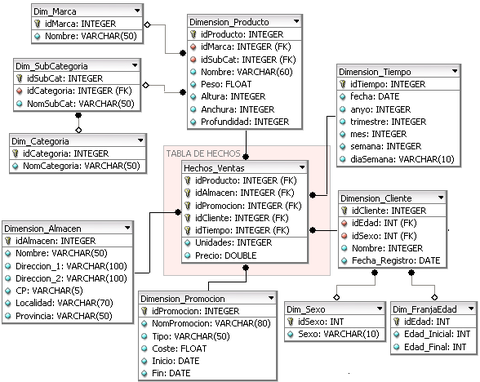
As this picture shows, everything is normalised in the 3NF, but is it necessary?
For example, in the dimension ‘client’ I would include the sex and the age group. Although these values would be duplicated many times, two joins would be saved.
In the dimension SubCategory I would add the data from Category even if the ‘category’ name would be duplicated.
Applying 3 recommendations 3 joins would have been saved for submitting a query about these dimensions.
Conclusion
We must not get obsessed with doing a super analysis, instead we will do a starting small analysis and start with a small data mart. That data mart will evolve as new business needs come and with every new report which makes us design the new data schema (consulting the transactional database).
We must not use denormalized supertables, ‘laugh now, cry later’. The amount of supertables increases over time, for example adding a key to a dimension which appears in 5 tables menas making 5 changes.
We must not get obsessed with having a very normalized snowflake schema, it will harm the queries when joins are made.
Using a star schema having common sense, for instance, if a dimension has a very high amount of keys a hybrid between the star and the snowflake schema can be used.
There are dimensions such as the ‘product’ dimension which contain data from the provider. We can decide to include all the data from the provider in the same ‘product’ table or separate it from ‘product’, thus having a new ‘provider’ dimension. (That is what I did).
We must apply common sense even if it is different for each one.
You can read other related posts:
- https://datamanagement.es/2020/03/30/fundamentos-de-las-bases-de-datos-relacionales-para-data-science-y-dummies/
- https://datamanagement.es/2020/03/10/powerbi-and-the-use-of-conditional-metrics/
- https://datamanagement.es/2020/03/10/programacion-orientada-a-objetos-para-data-science-avanzado/
- https://datamanagement.es/2020/01/29/iingenieria-de-datos-proyectos-big-data/
- https://datamanagement.es/2019/10/13/proceso-etl-con-python-desde-cero-y-paso-a-paso/
- https://datamanagement.es/2019/10/26/web-scraping-de-empresas-con-etl-en-python-y-powerbi/