Introducción
En el artículo https://datamanagement.es/2020/04/06/instalacion-de-sql-server-integration-services-ssis/ se explica qué és y para qué sirve SQL Server Integration Services – SSIS.
A partir de este artículo el objetivo es el de construir un proyecto completo de BI utilizando la SUITE de Microsoft. En este artículo voy a mostrar como construir un proceso ETL y cargar un Modelo de Estrella a partir de un Fichero Excel.
Descarga de recursos y proyecto: https://datamanagement.es/Recursos/SQL_Server_Integration_Service.7z
Creación de Datamart
Para la creación del Datamart se proporciona un fichero Excel con comercios y ventas de productos. El fichero contiene las ventas desnormalizadas de varios locales en España y a partir de este fichero se debe construir un DataMart.
/*
SCRIPT DE CREACIÓN DE TABLAS
En el caso de que una tabla no exista se crea y si no existiera se obvia la ejecución de creación
de tablas
*/
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='ds_ventas_excel')
CREATE TABLE ds_ventas_excel(
[Año] [float] NULL,
[Mes] [float] NULL,
[Establecimiento] [nvarchar](255) NULL,
[Dirección] [nvarchar](255) NULL,
[latitud] [float] NULL,
[longitud] [float] NULL,
[ZAPATILLAS] [nvarchar](255) NULL,
[PANTALONES] [float] NULL,
[GORRAS] [float] NULL,
[CARTERAS] [float] NULL,
[BOLLICAOS] [float] NULL,
[BOTIFARRAS] [float] NULL,
[FUET] [float] NULL
);
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='dw_dim_establecimiento')
CREATE TABLE [dbo].[dw_dim_establecimiento](
[id_establecimiento] [int] NOT NULL primary key,
[establecimiento] [nvarchar](255) NULL,
[direccion] [nvarchar](255) NULL,
[latitud] [float] NULL,
[longitud] [float] NULL,
[descri] [varchar](255) NULL,
[fecha_registro] [datetime] NULL,
[fecha_modificacion] [datetime] NULL
);
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='dw_dim_fecha')
CREATE TABLE dw_dim_fecha(
[id_fecha] [int] NOT NULL primary key,
[fecha] [date] NULL,
[ano] [int] NULL,
[trimestre] [char](2) NULL,
[ano_trimestre] [varchar](10) NULL,
[mes] [varchar](2) NULL,
[ano_mes] [varchar](10) NULL,
[dia] [varchar](2) NULL,
[dia_semana_number] [int] NULL,
[dia_semana_desc] [varchar](20) NULL
);
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='dw_dim_producto')
CREATE TABLE [dbo].[dw_dim_producto](
[producto] [nvarchar](255) NULL,
[id_producto] [int] primary key
);
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='dw_fact_ventas_1')
CREATE TABLE dw_fact_ventas_1(
[id_time] [varchar](11) NULL,
[id_establecimiento] [int] NULL,
[id_producto] [int] NULL,
[valor] [int] NULL
);
IF NOT EXISTS (SELECT
1
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE='BASE TABLE'
AND TABLE_NAME='dw_fact_ventas_2')
CREATE TABLE dw_fact_ventas_2(
[id_establecimiento] [int] NULL,
[id_time] [varchar](11) NULL,
[venta] [int] NULL,
[id_producto] [int] NULL
);En recursos se encuentra el fichero Excel con las ventas.

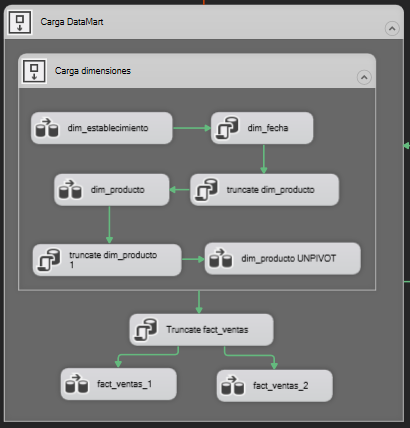
Esquema inicial del proyecto
Diseñar el esquema de la imagen, es la estructura que se siguen en los proyectos de PDI. Se va a realizar el mismo proceso de carga que se realiza con PDI pero con SSIS.
A partir de esta estructura se va a ir añadiendo funcionalidad a cada contenedor, los contenedores sirven para agrupar varios flujos de datos, tareas etc…
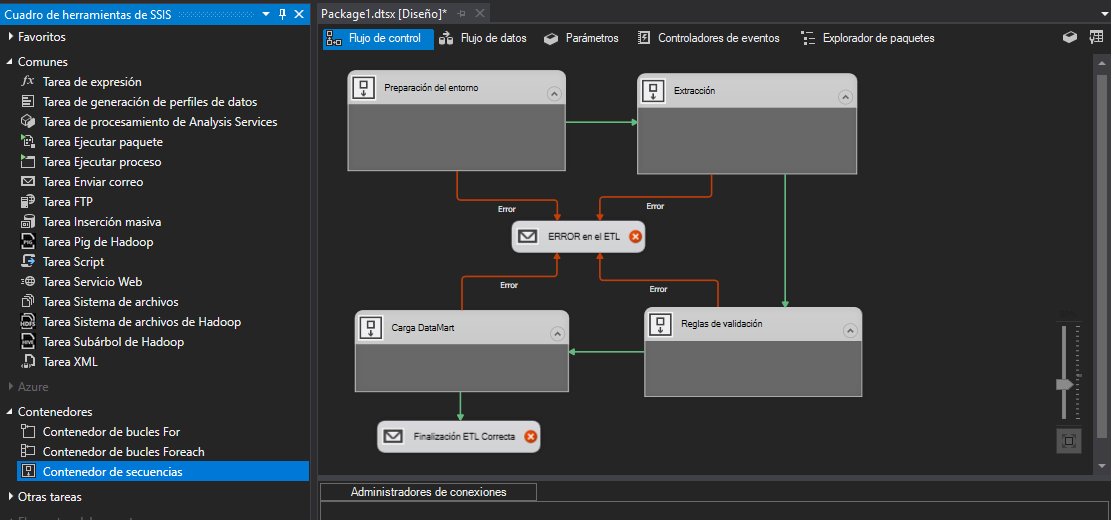
Crear conexiones
Para empezar con la práctica lo primero que se tiene que realizar es crear la conexión al fichero Excel que contiene la información y la conexión a la base de datos SQL Server que se ha instalado anteriormente.
En el siguiente enlace se explica los tipos de conexiones que tiene SSIS: https://docs.microsoft.com/es-es/sql/integration-services/connection-manager/integration-services-ssis-connections?view=sql-server-2017
En este enlace se explica las diferencias entre OLE DB Y ODBC que son los tipos de conexiones a BBDD distintas que se tiene en SSIS: https://www.ibm.com/support/knowledgecenter/es/SSULQD_7.1.0/com.ibm.nz.datacon.doc/c_datacon_introduction.html
Simplemente, OLE DB es una evolución de ODBC para dar soporte a otros tipos de BBDD y es diseñado por Microsoft. SSIS no tiene por defecto conexiones JDBC.
Conexión al fichero Excel
Enlace referencia: https://docs.microsoft.com/es-es/sql/integration-services/connection-manager/excel-connection-manager?view=sql-server-2017
Pulsar botón derecho en el administrador de conexiones y elegir el tipo de conexión EXCEL.

Seleccionar el fichero con los datos.

Conexión OLE DB a la BBDD de SQL Server de “formación”

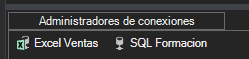
Renombrar la conexión a “SQL formacion”
Compartir las conexiones para toda la solución con el botón derecho.

Preparación del entorno
En la preparación del entorno se añaden los scripts de la creación de tablas en el caso de no existir. De esta forma la creación del Datamart sería con un simple click.
Añadir una tarea Ejecutar SQL para ejecutar el Script que se encuentra en la carpeta recursos>scripts sql
NOTA: La única pega es que la tarea se tiene que ejecutar manualmente o ejecutar el script por separado ya que si las tablas no existen SSIS es incapaz de ejecutar el paquete ETL porque hace referencia a tablas que no encuentra.
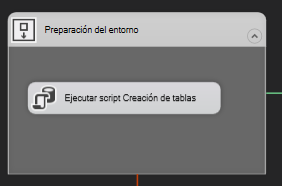

Extracción de los datos al área de Stage
Añadir un flujo de datos para extraer los datos de ventas del Excel e insertarlos en el área de Stage.








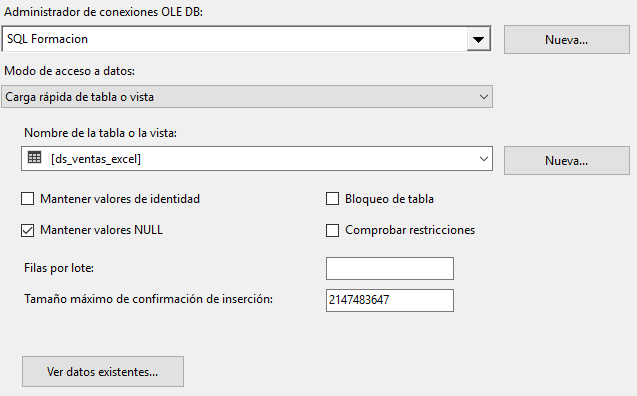
No hace falta crear la tabla ya que la ejecución del script del primer paso ya la ha creado, al igual que PDI, SSIS genera el Script de creación de tablas.
Para probar el flujo de datos pulsar con el botón derecho sobre cualquier parte del diseñador.
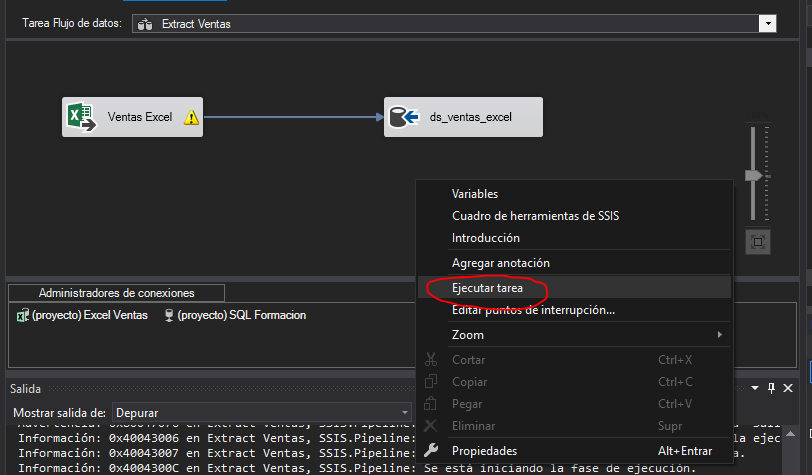

Comprobación de que los datos se han insertado.

Añadir un truncate table antes de ejecutar el flujo de datos para evitar duplicados y registros antiguos.

Carga de las dimensiones
Al tener los datos en el área de stage, ahora se identifican cuantas dimensiones hay y se cargan en las tablas dimensiones.

Se detectan 3 dimensiones:
- Dim_tiempo: se compone por año y mes
- Dimensión establecimiento: Establecimiento, dirección, latitud, longitud
- Producto: Esta dimensión se tiene que normalizar y pasar las columnas a filas.
Dimensión Establecimiento
Los campos clave del establecimiento son:
- Establecimiento
- Dirección
Y el resto de campos son:
- Latitud
- Longitud
Para cargar la dimensión establecimiento se hará una consulta mostrando los comercios distintos en la tabla desnormalizada, de esta forma no sobrecargamos a SSIS
-- Consultar los establecimientos distintos
select distinct
Establecimiento
, Dirección
, latitud
, longitud
from ds_ventas_excel
where Establecimiento is not null
order by Establecimiento asc;
Para la carga y sincronización de la dimensión se tiene que conseguir el siguiente Esquema que se explica detalladamente a continuación.
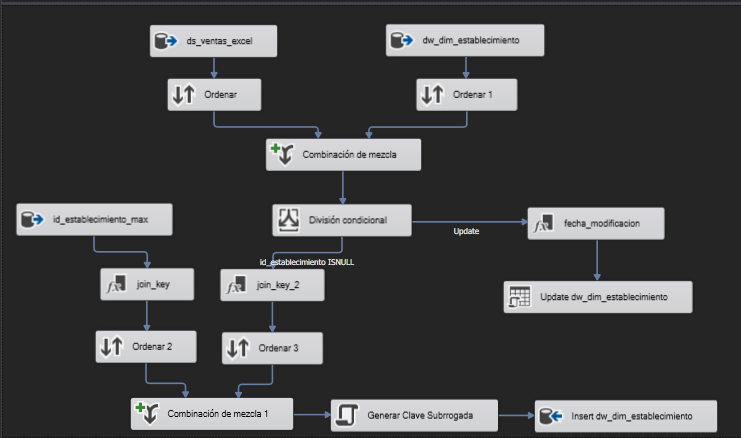
Ds_ventas_excel


dw_dim_establecimiento


Ordenar y Ordenar_1
Es necesario Ordenar por los campos clave de la dimensión ya que en pasos posteriores para realizar el Merge sobre estos campos es obligatorio hacer una ordenación.


Combinación de mezcla
Este paso es similar a un LEFT JOIN cruzando con los campos establecimiento y dirección. En la lista de campos de salida, para la tabla de la izquierda (la que viene del datastage) añado el sufijo “_new” a los campos y en la tabla de la derecha (la dimensión) añado el sufijo “_update” para comprobar después los registros distintos.
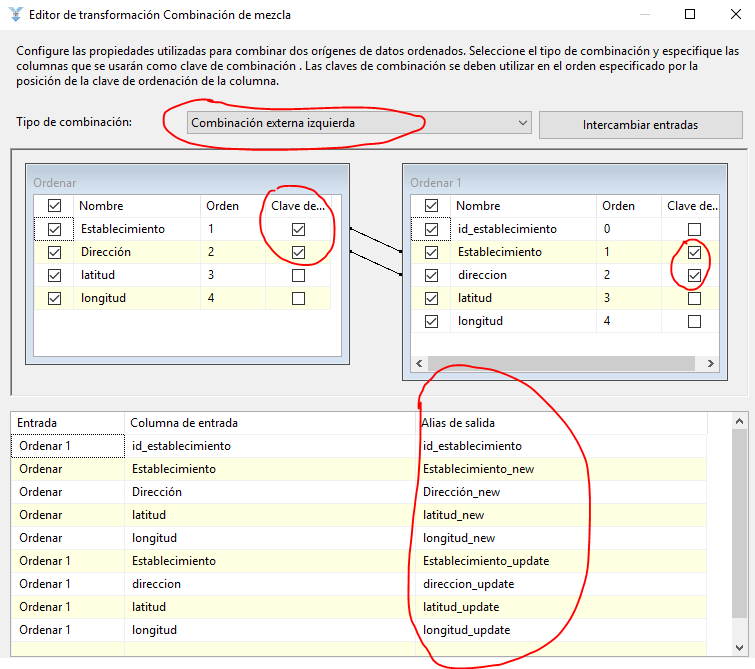
División condicional
Generar varios flujos de datos dependiendo de las condiciones.
- Si en el flujo de datos el campo id_establecimiento es nulo es porque el registro que viene del Datastage no existe en la dimensión
- Si los campos del datastage son distintos a los de la dimensión es porque ha cambiado algún registro y se tiene que actualizar
- Nombre de salida predeterminado: Los registros que no cumplen ninguna condición irán por este flujo

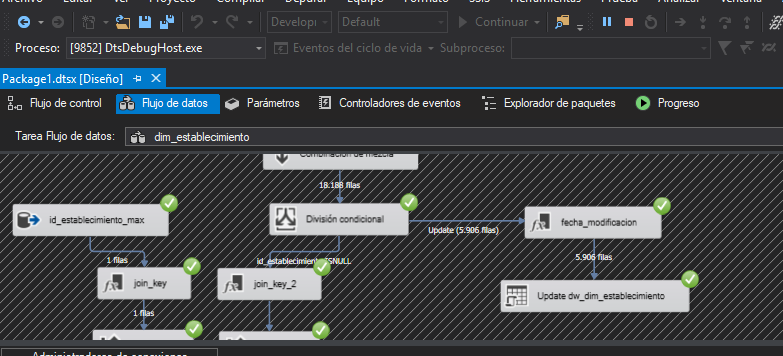
Insertar los registros nuevos
Después de añadir la división condicional se insertarán los registros nuevos a la dimensión. Para ello es necesario obtener el id máximo de la dimensión y generar una secuencia para sumar el número de la secuencia con el id máximo.

Id_establecimiento_max: Obtener el id_maximo de la dimensión.

Join_key: Este paso es obligatorio para poder hacer un producto cartesiano. Al no tener un componente de producto cartesiano es necesario añadir un campo con una constante, luego ordenar por esta constante y hacer el merge con este campo. De esta forma se consigue el mismo resultado que con el producto cartesiano.

Combinación de mezcla 1: Realizar el producto cartesiano con el campo añadido en el paso anterior y seleccionar los campos de salida para insertar más adelante.

Generar Clave Subrogada: Este es el paso más complejo ya que se hace uso de un Script C# para generar una secuencia y a partir del id_maximo de la dimensión sumar esta secuencia.

Añadir dos columnas de salida al paso:
- Id_max_sequence: será la suma de sequence y id_maximo
- Sequence: es la secuencia

Ahora editar el script, al pulsar sobre el botón se abre la ventana de edición de código de Visual Studio.

Añadir a la clase el atributo sequence inicializado a 0, este se irá incrementando por cada registro teniendo así una secuencia.

El método Entrada0_ProcessInputRow es llamado por cada registro, el objeto Row que recibe tiene todos los campos definidos anteriormente y se puede acceder al valor a través de Row.[propiedad | método].

Guardar el script y cerrar.
Actualización de dimensión
Con el flujo de datos que han modificado algunos de sus campos (excepto los campos clave), ahora se tiene que hacer un UPDATE de la dimensión.

Update dw_dim_establecimiento: Recibe los parámetros con los nuevos valores (distintos a los que hay en la dimensión) y actualiza con un Script SQL.

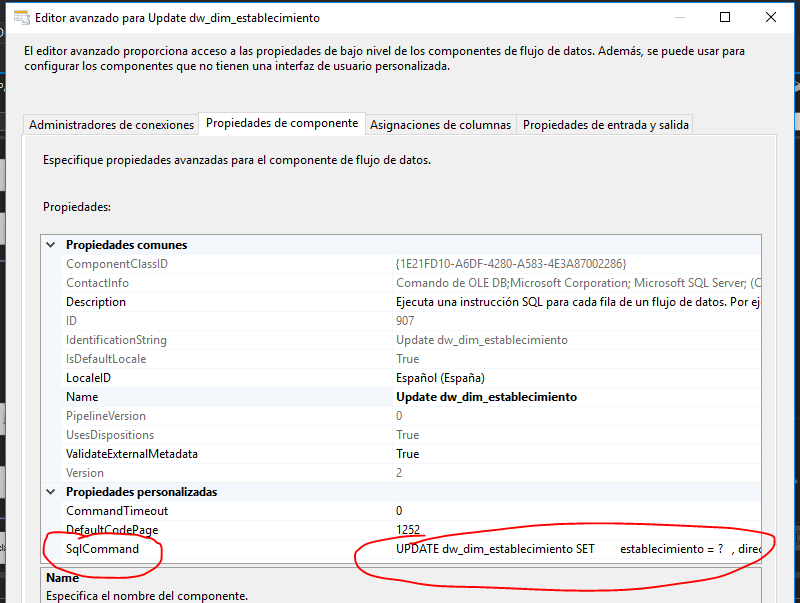
UPDATE dw_dim_establecimiento SET
establecimiento = ?
, direccion = ?
, latitud = ?
, longitud = ?
, fecha_modificacion = ?
WHERE id_establecimiento = ?
Unir los campos a los parámetros de la consulta y aceptar.

Ejecutar la tarea para comprobar que funciona.
Comprobación del proceso
Realizando la consulta se observan los siguientes datos
select
*
from dw_dim_establecimiento
order by id_establecimiento
Si modificamos los valores latitud y longitud y volvemos a ejecutar el proceso comprobamos que este actualiza los datos en vez de insertar un nuevo registro.
UPDATE dw_dim_establecimiento SET
latitud = 10.10
, longitud = 10.10
WHERE id_establecimiento IN (2, 3, 4, 5)

La siguiente prueba es borrar el id_establecimiento = 2 y comprobar que se inserta con un nuevo id (al final de la tabla) al ejecutar el proceso.
delete from dw_dim_establecimiento where id_establecimiento = 2
select
*
from dw_dim_establecimiento
order by id_establecimiento desc



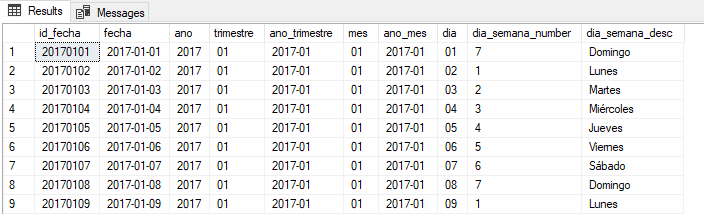
Dimensión Fecha
Para la carga de la dimensión fecha he programado un procedimiento almacenado que se encarga de cargar los datos en la tabla dw_dim_fecha
El Script de la creación de la tabla se encuentra en la carpeta Scripts.
El procedimiento es CargarDatos_DW_DIM_FECHA y se puede ejecutar de 2 formas ya que recibe 2 parámetros opcionales.
EXEC CargarDatos_DW_DIM_FECHA
EXEC CargarDatos_DW_DIM_FECHA
@fecha_ini = '2018-01-01'
, @fecha_fin = '2018-12-31'/*
Francisco Rodriguez Alfaro - fran@datamanagement.es
Carga los datos en la dimensión dw_dim_fecha
*/
CREATE PROCEDURE CargarDatos_DW_DIM_FECHA(
@fecha_ini date = '2018-01-01'
, @fecha_fin date = '2018-12-31'
)
AS
Begin
declare @fechas_tabla table (
fecha date
)
declare @dias_diferencia int = DATEDIFF(DAY, @fecha_ini, @fecha_fin) -- Obtener los dias de diferencia
declare @index int = 0
declare @fecha_aux date
-- select @fecha_ini, @fecha_fin, @dias_diferencia
WHILE @index <= @dias_diferencia BEGIN
set @fecha_aux = DATEADD(DAY, @index, @fecha_ini)
insert into @fechas_tabla (fecha)
values ( @fecha_aux )
SET @index = @index + 1
END
-- Truncar la tabla antes de insertar datos
TRUNCATE TABLE dw_dim_fecha;
INSERT INTO dw_dim_fecha ( id_fecha, fecha, ano, trimestre, ano_trimestre, mes, ano_mes, dia, dia_semana_number, dia_semana_desc )
SELECT
CAST( DATEPART( yyyy, fecha ) AS VARCHAR )
+ Right('0' + Cast( DATEPART( mm, fecha) As varchar(5)), 2)
+ Right('0' + Cast( DATEPART( dd, fecha) As varchar(5)), 2) AS 'ID_FECHA'
, fecha
, DATEPART( yyyy, fecha ) as 'ano'
, Right('0' + Cast( DATEPART( Qq, fecha) As varchar(5)), 2) AS 'TRIMESTRE'
, CAST( DATEPART( yyyy, fecha ) AS VARCHAR )
+ '-' + Right('0' + Cast( DATEPART( Qq, fecha) As varchar(5)), 5) AS 'ANO_TRIMESTRE'
, Right('0' + Cast( DATEPART( mm, fecha) As varchar(5)), 2) AS 'MES'
, CAST( DATEPART( yyyy, fecha ) AS VARCHAR )
+ '-' + Right('0' + Cast( DATEPART( mm, fecha) As varchar(5)), 2) AS 'ANO_MES'
, Right('0' + Cast( DATEPART( dd, fecha) As varchar(5)), 2) AS 'DIA'
, DATEPART( dw, fecha ) as 'dia_number'
, CASE
WHEN ( DATEPART( dw, fecha ) = 1 ) THEN
'Lunes'
WHEN ( DATEPART( dw, fecha ) = 2 ) THEN
'Martes'
WHEN ( DATEPART( dw, fecha ) = 3 ) THEN
'Miércoles'
WHEN ( DATEPART( dw, fecha ) = 4 ) THEN
'Jueves'
WHEN ( DATEPART( dw, fecha ) = 5 ) THEN
'Viernes'
WHEN ( DATEPART( dw, fecha ) = 6 ) THEN
'Sábado'
WHEN ( DATEPART( dw, fecha ) = 7 ) THEN
'Domingo'
END as 'dia_semana_desc'
FROM @fechas_tabla
END -- Cerrar procedimientoDesde SSIS hay que ejecutar el procedimiento almacenado enviando la fecha de inicio y fecha de fin al procedimiento. Las fechas de inicio y fecha de fin las vamos a guardar en variables.

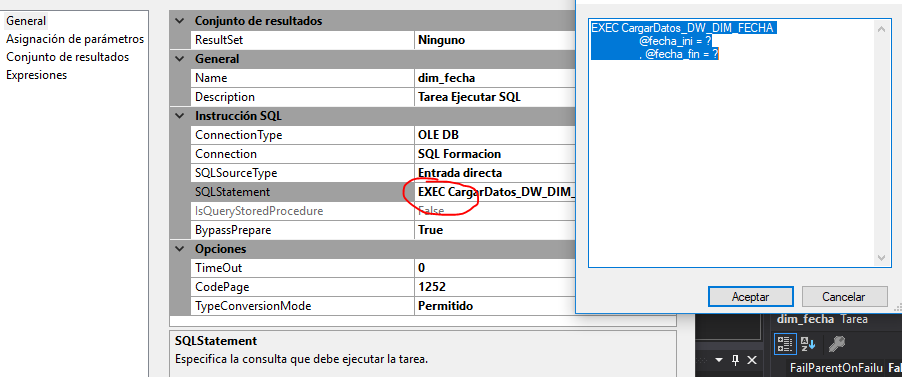
EXEC CargarDatos_DW_DIM_FECHA
@fecha_ini = ?
, @fecha_fin = ?
Asignar los parámetros para la ejecución del procedimiento almacenado. En el nombre de parámetro escribir el orden en el que aparece el parámetro. Comprobar que carga correctamente la dimensión.
Dimensión Productos
Esta dimensión es algo compleja ya que se tiene que normalizar las columnas y pasarlas a filas.

Para la normalización y carga de los productos se puede realizar de varias formas. Utilizando un paso para normalizar propio de SSIS o usando la función UNPIVOT de SQL SERVER.
Paso normalización SSIS:
select
CAST(REPLACE(ZAPATILLAS, '[NULL]', 0) AS VARCHAR(50)) AS 'ZAPATILLAS'
, CAST(REPLACE(PANTALONES, '[NULL]', 0) AS VARCHAR(50)) AS 'PANTALONES'
, CAST(REPLACE(GORRAS, '[NULL]', 0) AS VARCHAR(50)) AS 'GORRAS'
, CAST(REPLACE(CARTERAS, '[NULL]', 0) AS VARCHAR(50)) AS 'CARTERAS'
, CAST(REPLACE(BOLLICAOS, '[NULL]', 0) AS VARCHAR(50)) AS 'BOLLICAOS'
, CAST(REPLACE(BOTIFARRAS, '[NULL]', 0) AS VARCHAR(50)) AS 'BOTIFARRAS'
, CAST(REPLACE(FUET, '[NULL]', 0) AS VARCHAR(50)) AS 'FUET'
, 1 as 'auxiliar'
from ds_ventas_excel;
Realizar esta consulta para obtener todos los valores de los productos, después se hace la normalización de los datos pasando a filas las columnas


Este paso es muy similar al row normalizer de PDI.
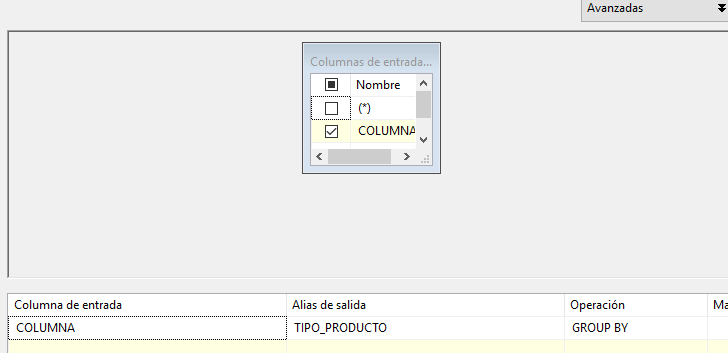
Después se hace un agrupado para obtener los distintos tipos de producto.
Y como se ha visto en la carga de la dimensión anterior, se hace uso del paso script para generar una secuencia y así darle el valor id a la dimensión.
Paso UNPIVOT SQL SERVER
Realizar la siguiente consulta SQL SERVER que automáticamente recibe una secuencia para cada tipo de producto distinto.
SELECT
PRODUCTOS as 'producto'
, ROW_NUMBER() OVER(ORDER BY PRODUCTOS ASC) AS 'id_producto'
FROM (
select DISTINCT
valores AS 'PRODUCTOS'
--, valor
FROM (
select
Establecimiento
, Dirección
, CAST(REPLACE(ZAPATILLAS, '[NULL]', 0) AS VARCHAR(50) ) AS "ZAPATILLAS"
, CAST(PANTALONES AS VARCHAR(50)) AS 'PANTALONES'
, CAST(GORRAS AS VARCHAR(50)) AS 'GORRAS'
, CAST(CARTERAS AS VARCHAR(50)) AS 'CARTERAS'
, CAST(BOLLICAOS AS VARCHAR(50)) AS 'BOLLICAOS'
, CAST(BOTIFARRAS AS VARCHAR(50)) AS 'BOTIFARRAS'
, CAST(FUET AS VARCHAR(50)) AS 'FUET'
from ds_ventas_excel
) as A1
UNPIVOT
( -- En valor se almacena el valor de la columna
-- En valores se almacenan los nombres de las columnas
valor FOR valores IN ( ZAPATILLAS, PANTALONES, GORRAS, CARTERAS, BOLLICAOS, BOTIFARRAS, FUET )
) AS prueba
) A
Realizar el insert a la tabla dw_dim_productos
Carga de la tabla de Hechos
Para la carga de la tabla de hechos he realizado dos formas posibles, una de ellas es hacer una consulta SQL realizando LEFT JOIN con las dimensiones para recuperar el ID de cada dimensión y la otra es realizando en el flujo de datos los JOIN con las tablas para recuperar los ID.
Fact_ventas_1
Esta carga de datos se realiza consultando a la BBDD y realizando LEFT JOIN con todas las dimensiones para obtener el ID de la dimensión. En la propia consulta SQL realizo UNPIVOT para normalizar los datos y pasar las columnas a filas.
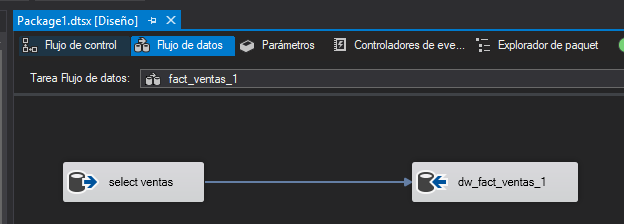
SELECT
CAST(A.año AS varchar(4)) + Right('0' + Cast( A.Mes As varchar(5)), 5) + '01' AS id_time
, B.id_establecimiento
, C.id_producto
, A.valor
FROM (
select
*
FROM (
select
Establecimiento
, Dirección
, latitud
, longitud
, año
, mes
, CAST(REPLACE(ZAPATILLAS, '[NULL]', 0) AS VARCHAR(50) ) AS "ZAPATILLAS"
, CAST(PANTALONES AS VARCHAR(50)) AS 'PANTALONES'
, CAST(GORRAS AS VARCHAR(50)) AS 'GORRAS'
, CAST(CARTERAS AS VARCHAR(50)) AS 'CARTERAS'
, CAST(BOLLICAOS AS VARCHAR(50)) AS 'BOLLICAOS'
, CAST(BOTIFARRAS AS VARCHAR(50)) AS 'BOTIFARRAS'
, CAST(FUET AS VARCHAR(50)) AS 'FUET'
from ds_ventas_excel
) as A1
UNPIVOT
( -- En valor se almacena el valor de la columna
-- En valores se almacenan los nombres de las columnas
valor FOR valores IN ( ZAPATILLAS, PANTALONES, GORRAS, CARTERAS, BOLLICAOS, BOTIFARRAS, FUET )
) AS prueba
WHERE valor > 0
) A
LEFT JOIN dw_dim_establecimiento B ON ( A.Establecimiento = B.Establecimiento
AND A.Dirección = B.direccion
AND A.latitud = B.latitud
AND a.longitud = B.longitud)
LEFT JOIN dw_dim_producto C ON ( A.valores = C.producto )
Fact_ventas_2
En este paso la transformación del flujo de datos se hace en el propio paso realizando una consulta simple con todos los campos y normalizar los datos en el flujo.

Productos desnormalizados: Consulta con todos los datos. Realizo el CAST para asegurarme de que todos los tipos son del tipo varchar. El UNPIVOT exige que todas las columnas que se normalizan deben tener el mismo tipo de datos.
select
Establecimiento
, Dirección
, latitud
, longitud
, año
, mes
, CAST(año AS varchar(4)) + Right('0' + Cast( Mes As varchar(5)), 5) + '01' AS id_time
, CAST(REPLACE(ZAPATILLAS, '[NULL]', 0) AS VARCHAR(50)) AS 'ZAPATILLAS'
, CAST(REPLACE(PANTALONES, '[NULL]', 0) AS VARCHAR(50)) AS 'PANTALONES'
, CAST(REPLACE(GORRAS, '[NULL]', 0) AS VARCHAR(50)) AS 'GORRAS'
, CAST(REPLACE(CARTERAS, '[NULL]', 0) AS VARCHAR(50)) AS 'CARTERAS'
, CAST(REPLACE(BOLLICAOS, '[NULL]', 0) AS VARCHAR(50)) AS 'BOLLICAOS'
, CAST(REPLACE(BOTIFARRAS, '[NULL]', 0) AS VARCHAR(50)) AS 'BOTIFARRAS'
, CAST(REPLACE(FUET, '[NULL]', 0) AS VARCHAR(50)) AS 'FUET'
, 1 as 'auxiliar'
from ds_ventas_excel;
dw_dim_establecimiento: Consultar esta tabla para cruzar con un LEFT JOIN más adelante.
Merge: Realizar una combinación externa izquierda (LEFT JOIN) para recuperar el ID de la dimensión establecimiento y seleccionar todos los campos de la tabla izquierda.

Anulación de dinamización: Es el paso UNPIVOT, el que realiza la normalización y pasa a filas las columnas.

Dw_dim_producto: Consulta de la tabla.
Merge_2: Realizar la combinación de mezcla (INNER JOIN) con la dimensión producto para obtener el id_producto.

Venta > 0: Condición para obtener solamente las ventas > 0

Dw_fact_ventas_2: Insertar en esta tabla los datos que vienen por el flujo venta.
Comprobar el resultado de ambos procesos de carga de hechos
Realizar un par de comprobaciones con la BBDD para corroborar que la información insertada en ambos procesos es la misma.
Esta consulta es de dw_fact_ventas_1
-- ventas 1, tabla UNPIVOT en la consulta SQL
select
id_time, B.producto, C.establecimiento
, count(*) as cantidad
, sum(valor) as valores
from dw_fact_ventas_1 A
left join dw_dim_producto B ON ( A.id_producto = B.id_producto )
left join dw_dim_establecimiento C ON ( A.id_establecimiento = C.id_establecimiento )
group by id_time, B.producto, C.establecimiento
order by count(*) desc, id_time, B.producto, C.establecimiento— ventas 1, tabla UNPIVOT en la consulta SQL
Esta consulta es de dw_fact_ventas_2
-- ventas 2, proceso UNPIVOT en el paquete
select
id_time, B.producto, C.establecimiento
, count(*) as cantidad
, sum(venta) as valores
from dw_fact_ventas_2 A
left join dw_dim_producto B ON ( A.id_producto = B.id_producto )
left join dw_dim_establecimiento C ON ( A.id_establecimiento = C.id_establecimiento )
group by id_time, B.producto, C.establecimiento
order by count(*) desc, id_time, B.producto, C.establecimientoEl resultado de las consultas es el siguiente

Conclusión
Descarga de recursos y proyecto: https://datamanagement.es/Recursos/SQL_Server_Integration_Service.7z
En este artículo se ha desarrollado un proceso ETL completo a partir de un fichero Excel con datos de venta ficticios.
El objetivo para el siguiente artículo es montar un cubo de Analysis Services utilizando estos datos y después conectar powerBI al cubo de Analysis Services.